- #1
evinda
Gold Member
MHB
- 3,836
- 0
Hello! (Wave)
Given a binary search tree $B$, I want to write an algorithm, that divides $B$ into two new trees $B_1, B_2$, so that the first one contains all the keys of $B$ that are smaller than $k$ and the second one contains all the keys of $B$ that are greater than $k$.
Hint : Execute a search of $k$, "cutting out" the pointers that "hang" at the left side and the right side of the path. After that, merge the trees of the forest, you get.
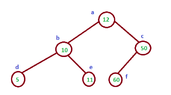
I tried to find like that, the position, at which $k$ is:
Is it right? Or have I done something wrong? (Thinking)
Given a binary search tree $B$, I want to write an algorithm, that divides $B$ into two new trees $B_1, B_2$, so that the first one contains all the keys of $B$ that are smaller than $k$ and the second one contains all the keys of $B$ that are greater than $k$.
Hint : Execute a search of $k$, "cutting out" the pointers that "hang" at the left side and the right side of the path. After that, merge the trees of the forest, you get.
I tried to find like that, the position, at which $k$ is:
Code:
if (B==k) p=B;
else if (B>k){
while (B->left>x){
B=B->left;
}
p=B;
else if (B<x){
while (B->right<x){
B=B->right;
}
p=B;
}Is it right? Or have I done something wrong? (Thinking)