- #1
Malamala
- 299
- 26
Hello! I have the to fit a curve to the attached data (I plotted it both with and without error bars), where the error bars are Poisson errors i.e. ##\sqrt{N}##, where ##N## is the number of counts in the given bin. I want to fit 3 Gaussians + background and extract the values (and errors associated) of the 3 means and 3 standard deviations. This is the raw data that I was provided with i.e. I was given the number of counts for each value of the x-axis (I don't have the individual values for each element in each bin). What is the best way to fit it? There are many bins with very low count, so I can't assume that the Poisson error is a Gaussian there (<10 data points) so doing a least-square fit might be a bit tedious. Also I am not sure how well it would perform, given that the relative errors are quite big so the relative errors on the parameters of the fit will also be large. I was thinking to re-bin the data. I would reduce the relative error in each bin, but I am not sure what is the right way to do it. Different binnings give slightly different values for the means and standard deviations and I am not sure which one should I pick or how to combine the values from different binnings to give a final value. I guess I can't use max-likelihood here, given that I don't have the individual measurements. What should I do? Thank you!

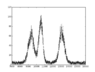
") ) works out an example of a peak on a quadratic background.
) works out an example of a peak on a quadratic background.


 also a bit because it prevents me from plotting the three peaks and thus visualizing my 'exactly the same' claim)
also a bit because it prevents me from plotting the three peaks and thus visualizing my 'exactly the same' claim)