FactChecker
Science Advisor
Homework Helper
- 9,500
- 4,751
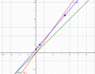
Below is a simple example to illustrate the pros and cons of the two regression models.
Suppose: Suppose the true physics without any random behavior is the green (truth) line Y=X, and suppose we know from theory that it goes through (0,0). Two sample data points, ##S_1## and ##S_2## include some random behavior which puts them above the truth line and forces the typical regression (blue line, ##regr_1##) to have a nonzero Y-axis intercept at point Int. Suppose the restricted red regression line (##reg_2## through (0,0)) is calculated because we theoretically know that Y=0 when X=0 if there is no random behavior.
Then: The red line gives better estimates near (0,0) and worse estimates farther away. Also, its slope is worse. But it has one advantage when challenged by skeptical people -- it is correct at the Y-intercept, where a theoretical answer is known. I would prefer to avoid using the blue line as my model when it is undeniably wrong at the Y-intercept. But that depends on how the model is used. If accuracy far from the Y-intercept is more important than accuracy near the Y-intercept, then you may prefer the model that ignores the known theory of the Y-intercept value.

Suppose: Suppose the true physics without any random behavior is the green (truth) line Y=X, and suppose we know from theory that it goes through (0,0). Two sample data points, ##S_1## and ##S_2## include some random behavior which puts them above the truth line and forces the typical regression (blue line, ##regr_1##) to have a nonzero Y-axis intercept at point Int. Suppose the restricted red regression line (##reg_2## through (0,0)) is calculated because we theoretically know that Y=0 when X=0 if there is no random behavior.
Then: The red line gives better estimates near (0,0) and worse estimates farther away. Also, its slope is worse. But it has one advantage when challenged by skeptical people -- it is correct at the Y-intercept, where a theoretical answer is known. I would prefer to avoid using the blue line as my model when it is undeniably wrong at the Y-intercept. But that depends on how the model is used. If accuracy far from the Y-intercept is more important than accuracy near the Y-intercept, then you may prefer the model that ignores the known theory of the Y-intercept value.
Attachments
Last edited: