dgsfbandeira
- 12
- 4
- TL;DR
- Is there a way to reverse find the one that is missing? I mean, is there a function that would give me the value that, amongst the 54 values found, would fit and give me the MEAN and SD I have?
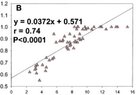
I have a scatterplot that I'm trying to extract. I found 54 values out of 55.
There is one "missing" value, probably because it is overlapped and I can't actually see.
I have the MEAN and Stand Dev of the 55 values.
Is there a way to reverse find the one that is missing? I mean, is there a function that would give me the value that, amongst the 54 values found, would fit and give me the MEAN and SD I have?
PLEASE!
(preferably a function in excel),
There is one "missing" value, probably because it is overlapped and I can't actually see.
I have the MEAN and Stand Dev of the 55 values.
Is there a way to reverse find the one that is missing? I mean, is there a function that would give me the value that, amongst the 54 values found, would fit and give me the MEAN and SD I have?
PLEASE!
(preferably a function in excel),