SUMMARY
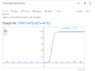
The positive-only sigmoid function is primarily utilized in neural networks due to its ability to provide a monotonically increasing output, typically ranging from 0 to 1. This characteristic allows for effective modeling of biological systems by introducing non-linearity, which is essential for simulating complex behaviors in neural networks. The standard equation for this function is 1.0 / (1.0 + e^(-x)). Its design facilitates the activation of nodes, enabling them to represent varying degrees of activation, which is crucial for learning and error correction in neural network architectures.
PREREQUISITES
- Understanding of neural network architecture
- Familiarity with activation functions, specifically the sigmoid function
- Basic knowledge of mathematical concepts, including exponential functions
- Experience with programming frameworks for neural networks, such as TensorFlow or PyTorch
NEXT STEPS
- Research the implementation of the sigmoid activation function in TensorFlow 2.x
- Explore the differences between sigmoid and other activation functions like ReLU and Tanh
- Learn about the impact of activation functions on neural network convergence
- Investigate advanced techniques for tuning activation functions in deep learning models
USEFUL FOR
Data scientists, machine learning engineers, and anyone involved in designing or optimizing neural networks will benefit from this discussion, particularly those focusing on activation functions and their effects on model performance.