evinda said:
We will have something like that, right?
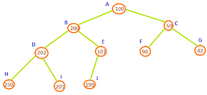
View attachment 3562
After that, why do we execute the commands [m] print(C->data)[/m] and [m]Pr(C->lc)[/m]?
If there were also other commands, after the command [m]Pr(P->lc)[/m], would they be executed for G or would the [m]G[/m] node be again fully processed? (Thinking)
It seems to me that the missing concept in your understanding is the idea of a
stack. The basic idea of a stack is simple: last in, first out. That is, the last thing you put on the stack is the first thing you take off it. Think of one of those cafeteria tray stacks with the springs under them, or like what some restaurants have with springs underneath plates. "Pushing" is the act of putting something on the stack, and "popping" is the act of taking something off the stack. A stack is to be contrasted with a linked list, where the first thing you put in the last is the first thing you would take off the list (first in, first out).
Now then, when you call a function in a language, all sorts of things happen, but one thing that happens is that there is a place in the computer where the execution control is (what's going to be executed next). This is the
"call stack". It tells you what will execute next.
When you use a recursive function like [m]Pr[/m], the call stack is absolutely essential to understanding what's going to happen next. I'm going to see if I can illustrate with a little table of execution here. The code will be on the left, and the stack will be on the right. The "top" of the stack will be to the right, and the Call Stack State will be what the call stack looks like after the corresponding code to the left
finishes executing. Also, you have to keep track of which function instance is currently running, so I'll do that with dot notation. "Pr(A).statement" means that "statement" is executing in the "Pr(A)" instance.
[table="width: 700, align: left"]
[tr]
[td]
Code Executing [/td]
[td]
Call Stack State (top is to the right)[/td]
[/tr]
[tr]
[td]Pr(A)[/td]
[td]Pr(A) (pushing Pr(A) onto the stack)[/td]
[/tr]
[tr]
[td]Pr(A).(A==NULL) False[/td]
[td]Pr(A)[/td]
[/tr]
[tr]
[td]Pr(A).Pr(C)[/td]
[td]Pr(A), Pr(C) (pushing Pr(C) onto the stack)[/td]
[/tr]
[tr]
[td]Pr(C).(C==NULL) False[/td]
[td]Pr(A), Pr(C)[/td]
[/tr]
[tr]
[td]Pr(C).Pr(G)[/td]
[td]Pr(A),Pr(C),Pr(G) (pushing Pr(G) onto the stack)[/td]
[/tr]
[tr]
[td]Pr(G).(G==NULL) False[/td]
[td]Pr(A), Pr(C),Pr(G)[/td]
[/tr]
[tr]
[td]Pr(G).Pr(G->rc) [/td]
[td]Pr(A),Pr(C),Pr(G),Pr(G->rc) (pushing Pr(G->rc) onto the stack)[/td]
[/tr]
[tr]
[td]Pr(G->rc).(G->rc==NULL) True[/td]
[td]Pr(A),Pr(C),Pr(G),Pr(G->rc)[/td]
[/tr]
[tr]
[td]Pr(G->rc).return [/td]
[td]Pr(A),Pr(C),Pr(G) (popping Pr(G->rc) off the stack) [/td]
[/tr]
[tr]
[td]Pr(G).print(G->data) (42) [/td]
[td]Pr(A),Pr(C),Pr(G)[/td]
[/tr]
[tr]
[td]Pr(G).Pr(G->lc) [/td]
[td]Pr(A),Pr(C),Pr(G),Pr(G->lc) (pushing Pr(G->lc) onto the stack)[/td]
[/tr]
[tr]
[td]Pr(G->lc).(G->lc==NULL) True[/td]
[td]Pr(A),Pr(C),Pr(G),Pr(G->lc)[/td]
[/tr]
[tr]
[td]Pr(G->lc).return[/td]
[td]Pr(A),Pr(C),Pr(G) (popping Pr(G->lc) off the stack)[/td]
[/tr]
[tr]
[td]Pr(G).} (end of routine) [/td]
[td]Pr(A),Pr(C) (popping Pr(G) off the stack)[/td]
[/tr]
[tr]
[td]Pr(C).print(C->data) (50) [/td]
[td]Pr(A),Pr(C)[/td]
[/tr]
[tr]
[td]Pr(C).Pr(F) [/td]
[td]Pr(A),Pr(C),Pr(F) (pushing Pr(F) onto the stack)[/td]
[/tr]
[tr]
[td]Pr(F).(F==NULL) False[/td]
[td]Pr(A),Pr(C),Pr(F)[/td]
[/tr]
[tr]
[td]Pr(F).Pr(F->rc) [/td]
[td]Pr(A),Pr(C),Pr(F),Pr(F->rc) (pushing Pr(F->rc) onto the stack)[/td]
[/tr]
[tr]
[td]etc.[/td]
[td][/td]
[/tr]
[/table]
Hopefully, if you have your latest version of your code, and the tree itself in front of you, and you compare this table of execution with those carefully, it will help you to see what's going on. Does this help?
You really have to have multiple levels of abstraction in your mind simultaneously in order to understand recursion.