jonnybgood66
- 11
- 0
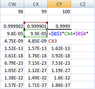
Here's the actual problem I'm faced with. Suppose a segment of dna with 100 mutations (SNPs) which occur at different frequencies from each other and between 2 different populations for the same mutation. The expected number of mutations occurring in the segment of dna is different in either population, and using this difference I can predict from which population the segment originates. I need to determine the intersection/low point between the 2 frequency curves at which I can say, to the left of this point the segment is assigned to Pop 1, to the right of this point it's assigned to Pop 2. I've managed to do this by generating thousands of simulated curves with RND. But this causes the run time to increase by half an hour, which is unacceptable. That's when I started looking into trying to calculate this curve. From what I've read, the binomial distribution is clearly what I want, except for one thing, it assumes p is constant. In my problem, every p is different. Is this possible to calculate? [I have a feeling it isn't]
PS: I've glanced over the Beta-binomial distribution, but it seems to involve a random p. In my example, I have a known value for p for each of the k trials/events, and I need to use those exact p values.
PS: I've glanced over the Beta-binomial distribution, but it seems to involve a random p. In my example, I have a known value for p for each of the k trials/events, and I need to use those exact p values.