- #1
DaveC426913
Gold Member
- 22,497
- 6,168
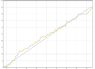
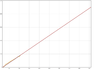
I've got a collection of data that contains observations over time. I want to predict when a given future observation is likely to occur.
As a simple example: Say I'm watching billiard balls drop into a pocket. The billiard balls drop in with approximate regularity.
My dataset:
1 ball 0:00
2 ball 0:57
3 ball 2:02
4 ball 2:48
5 ball (not observed)
6 ball (not observed)
7 ball 5:55
8 ball (not observed)
9 ball 7:40
...
n ball ?
Understand that when the 9 ball drops at 7:40, I know it is the 9 ball. This means I know the 8 ball (and 5 and 6) went in the pocket, even though I didn't observe it and don't know when it did so.
These observations are ongoing, so, after each ball, I will update the prediction, getting ever more accurate as I get more data.
I want to create an algorithm that will predict when ball n (say, ball 25) is expected to drop.
BTW, I am better at programming than math, so I am more comfortable with an algorithm (sequential steps) that a formula.
As a simple example: Say I'm watching billiard balls drop into a pocket. The billiard balls drop in with approximate regularity.
My dataset:
1 ball 0:00
2 ball 0:57
3 ball 2:02
4 ball 2:48
5 ball (not observed)
6 ball (not observed)
7 ball 5:55
8 ball (not observed)
9 ball 7:40
...
n ball ?
Understand that when the 9 ball drops at 7:40, I know it is the 9 ball. This means I know the 8 ball (and 5 and 6) went in the pocket, even though I didn't observe it and don't know when it did so.
These observations are ongoing, so, after each ball, I will update the prediction, getting ever more accurate as I get more data.
I want to create an algorithm that will predict when ball n (say, ball 25) is expected to drop.
BTW, I am better at programming than math, so I am more comfortable with an algorithm (sequential steps) that a formula.

")