Dan Zar
- 8
- 0
Homework Statement
Hello,
I am using CasaXPS to model synthetic peak models for X-ray photoelectron spectroscopy data. I am fitting.
The software has a lot of manuals online but they do not explain how they yield a Residual Standard Deviation, after each fit iteration. Most software use Chi-square or Reduced-Chi-squares, which I do not really understand either, but they are more widely used.
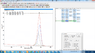
For example,
Whereas most softwares use Reduced Chi squares.
Lastly,Name Block Id Data Set Position FWHM Area St Dev Area %At Conc % St.Dev. Goodness of Fit
sp2 C1s 1-1 12 284.4560 1.1348 135.671 8.38179 54.79 286.976
sp3 C1s 1-1 285.0000 1.2000 89.8416 8.55699 36.28 286.976
sp2-Br C1s 1-1 285.6874 1.2000 14.7421 5.73433 5.95 286.976
C=P C1s 1-1 284.4843 0.9000 7.37342 2.8681 2.98 286.976 I get a report in which the "Goodness of Fit" equals 286.976, how do I transform this number into something statistically significant?
The examples they use on the manuals also happen to have high numbers for "Goodness of Fit"
Thanks a lot.