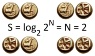fbs7
- 345
- 37
jbriggs444 said:The mathematical criterion did not change. An algorithm "exists" whether it is known or not.
Ah, I see! Good point!
Now, how about this question; say that P is the set of all possible programs for some given machine; P is certainly infinite. Then for a certain string s we want to consider algorithms p ∈ P whose size(p) < size(s); we don't want to consider algorithms that are too big. Even so, the number of algorithms will be immense; if that string is 1,000,000 bytes, then the programs cannot be more than say 500,000 bytes, therefore, that will be up to 256^500,000 programs, or 10106. Then how to prove that among that gazillion of programs there isn't any program that will compress that string to 500,000 bytes.
This criteria seems very interesting, but I suspect the application of it may be challenging at best! I'm so happy I didn't become an Information Theory guy, because my poor old brain would be fried many times in the first week!