- #1
evinda
Gold Member
MHB
- 3,836
- 0
Hello! (Wave)
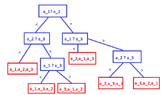
In my notes there is the following decision tree:
View attachment 3838
Could you explain me how it is constructed? (Thinking)
In my notes there is the following decision tree:
View attachment 3838
Could you explain me how it is constructed? (Thinking)