- #1
BWV
- 1,465
- 1,781
This paper getting some press, with promises that NNs can crack Navier-Stokes solutions more efficiently than traditional numerical methods.
https://www.technologyreview.com/20...er-stokes-and-partial-differential-equations/
https://arxiv.org/abs/2010.08895
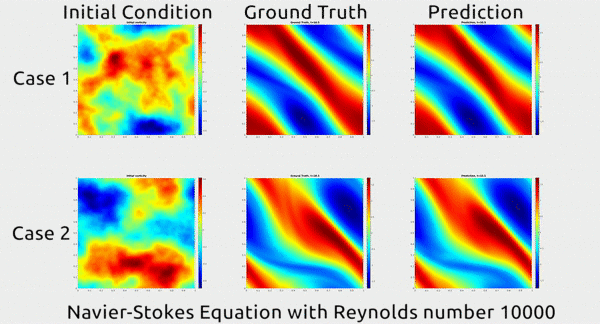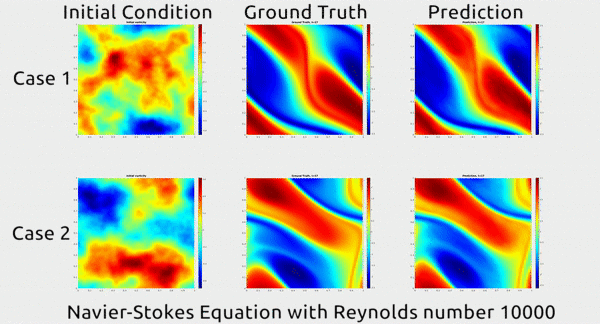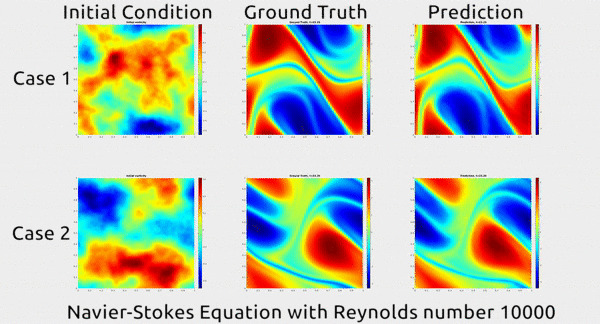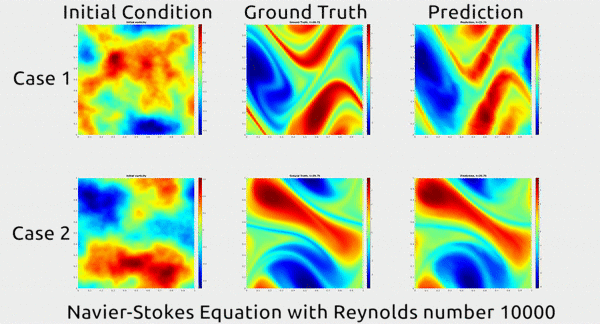
Now researchers at Caltech have introduced a new deep-learning technique for solving PDEs that is dramatically more accurate than deep-learning methods developed previously. It’s also much more generalizable, capable of solving entire families of PDEs—such as the Navier-Stokes equation for any type of fluid—without needing retraining. Finally, it is 1,000 times faster than traditional mathematical formulas, which would ease our reliance on supercomputers and increase our computational capacity to model even bigger problems
... In the gif below, you can see an impressive demonstration. The first column shows two snapshots of a fluid’s motion; the second shows how the fluid continued to move in real life; and the third shows how the neural network predicted the fluid would move. It basically looks identical to the second.
https://www.technologyreview.com/20...er-stokes-and-partial-differential-equations/
https://arxiv.org/abs/2010.08895