Hi fresh:
I have just realized that I had misunderstood the quote below.
fresh_42 said:
Can you show us how you derived this result - in mathematics, not in excel?
I had interpreted this as telling me that the spreadsheet approach was not acceptable, and that I needed to present a solution using mathematics. I now understand that what you were telling me was that I needed to include a mathematical explanation of what I was doing in the spreadsheet. I apologize for my denseness.
Here is my attempt to give a mathematical explanation of my spreadsheet images in my post #96, which I have edited to correct typos in the spreadsheet images.
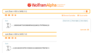
Column A
Whole numbers represent the number of the day of daytime growth of the tree starting at day 0 when the tree's height was 10000 cm.
Numbers with .5 represents the nighttime of the immediately preceding entry daytime, and corresponds to the nighttime in which the beetle climbs.
Column B
These values show the height of the tree on the day shown in Column A.
Also in the second image starting with cell B4 and continuing in all lower cells is the formula
=B(k)+20
where k refers to the row of the cell two above the formula. This shows the calculation of the height of the tree by adding 20 cm to the previous day's height.
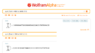
Column C
These values show the height on the tree to which the beetle has climbed on the day shown in Column A. The increases in the height value occur in both rows with and without the ".5" in Column A. In Column C with rows without ".5" in Column A, the increment in Column C calculates the increase in the beetles height due to the tree growth. The formula in cell C4,
=C3*B4/B3,
shows that the previous beetle height is multiplied by the ratio of the previous tree height to the current tree height. In Column C with rows with ".5" in Column A, the increment in Column C calculated the increase in the beetles height due to the beetles climb that night. The formula in Cell C5,
=$C$3+C4,
shows the beetle's height following the previous night's climb is added to the value in Cell C3 which is the constant 10cm of a nightly beetle climb.
Column D
These values (after Cell D1) show the ratio of the tree height (Column B) with the beetle's height (Column C). The formula in these cells show the calculation of these ratios. The bottom image shows the rows preceding and including the row in which the ratio value in Cell D6385 exceeds 1. The value in Cell A6385 shows that the beetle reached to top of the tree during its nightly climb on day 3191.
BTW: The quote below from your post #101.
fresh_42 said:
The least lower bound are 3184 nights, which I got by nested intervals and wolframalpha.
gives the day the beetle reaches the tree top as 3184. I attempted to reproduce this in a spreadsheet calculating
ln(499) = 6.21260609575152
ln(3687) = 8.21256839823415
ln(3688) = 8.21283958467648
ln(3687)-ln(499) = 1.99996230248263
ln(3688)-ln(499) = 2.00023348892496
3688-499 = 3189
I then also calculated for the following sums for n=3190 and n=3191.
[NOTE: CORRECTIONS MADE TO NEXT TWO LINES.]
For n = 3190: ##\sum_{i=0}^n 1/(500+k)## = 1.99990946718039
For n = 3191:##\sum_{i=0}^n 1/(500+k)## = 2.00018039646784
It appears that 3191 is more correct than either 3184 or 3189.
Regards,
Buzz