- #1
kidsasd987
- 143
- 4
Hello, I want to verify this question.
In short,
"Where did input matrix Bu arise from?"
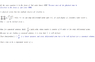
I was wondering why the state equation has to be in the form of x_dot=Ax+Bu. I got to the point that the highest order terms can be expressed in the form of linear superposition of lower degree terms.
If that is the case, we can find dim(x)=n. (state vector in R^n)
Also because d/dt is a linear operator, dim(x_dot)=dim(x) (because we need n terms to uniquely determine x_dot).
And this gives a conclusion that dim(A)+dim(B)=dim(x). which means, Bu is compensating dimension for the 2nd order differential terms (since x_dot's 2nd order terms are linear superposition of lower differential terms)
Professor told me that, x_dot doesn't need to be in the same dimension in the case that if A has a nullity greater than 1 (A doesn't have full rank)
but considering the canonical solution, wouldn't they have to be in the same dimension?
In short,
"Where did input matrix Bu arise from?"
I was wondering why the state equation has to be in the form of x_dot=Ax+Bu. I got to the point that the highest order terms can be expressed in the form of linear superposition of lower degree terms.
If that is the case, we can find dim(x)=n. (state vector in R^n)
Also because d/dt is a linear operator, dim(x_dot)=dim(x) (because we need n terms to uniquely determine x_dot).
And this gives a conclusion that dim(A)+dim(B)=dim(x). which means, Bu is compensating dimension for the 2nd order differential terms (since x_dot's 2nd order terms are linear superposition of lower differential terms)
Professor told me that, x_dot doesn't need to be in the same dimension in the case that if A has a nullity greater than 1 (A doesn't have full rank)
but considering the canonical solution, wouldn't they have to be in the same dimension?
Attachments
Last edited: