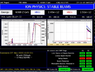
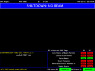
- 37,487
- 14,377
It is. Most collisions are quite soft, however, and most analyses look for hard interactions that produce high energy particles.
With charged particles (especially muons and electrons) you have nice tracks pointing to the right primary vertex. With uncharged particles it is more difficult.
The worst case is the transverse momentum balance, where you look for particles that don't interact with the detector at all via conservation of momentum (see here, the part on supersymmetry). You can easily get a wrong result if you assign particles to the wrong primary vertex.
All four big detectors will replace/upgrade their innermost detectors to handle more collisions per bunch crossing in the future.
---
ATLAS and CMS reached 25/fb, with a bit more protons per bunch we reached 140% of the design luminosity and very stable running conditions. The better focusing is in place and works.
---
Edit Friday: 126 billion protons per bunch, should be a new record. About 160% the design luminosity at the start of the run - with just 1916 bunches (1909 colliding in ATLAS and CMS). About 60 (inelastic) proton-proton collisions per bunch crossing (75 if we count elastic scattering).
BCMS could increase this even more.
The detectors were designed for 25 collisions per bunch crossing.
LHCb reached 1/fb.
With charged particles (especially muons and electrons) you have nice tracks pointing to the right primary vertex. With uncharged particles it is more difficult.
The worst case is the transverse momentum balance, where you look for particles that don't interact with the detector at all via conservation of momentum (see here, the part on supersymmetry). You can easily get a wrong result if you assign particles to the wrong primary vertex.
All four big detectors will replace/upgrade their innermost detectors to handle more collisions per bunch crossing in the future.
---
ATLAS and CMS reached 25/fb, with a bit more protons per bunch we reached 140% of the design luminosity and very stable running conditions. The better focusing is in place and works.
---
Edit Friday: 126 billion protons per bunch, should be a new record. About 160% the design luminosity at the start of the run - with just 1916 bunches (1909 colliding in ATLAS and CMS). About 60 (inelastic) proton-proton collisions per bunch crossing (75 if we count elastic scattering).
BCMS could increase this even more.
The detectors were designed for 25 collisions per bunch crossing.
LHCb reached 1/fb.
Last edited: