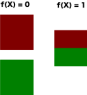mXSCNT
- 310
- 1
"Subtracting out" a random variable
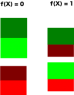
let X be a discrete R.V. and let Y = f(X) for some function f. I wish to find a function g, such that Y and Z = g(X) are independent, and also such that the uncertainty H(Z) is maximized. For example, suppose X is uniformly distributed over {0,1,2,3,4,5,6,7} and f(x) = 0 if x < 4, f(x) = 1 otherwise. Then if we let g(x) = x mod 4, g satisfies the requirements in this example. One could interpret Z as the distribution X from which the distribution Y has been "subtracted out." Encoding the values of X in binary as 000,001,010,011,100,101,110,111, we see that f extracts the left bit of X, and g extracts the remaining two bits.
However, this is not always possible; for example suppose X is uniformly distributed over {0,1,2} and f(x) = 1 if x == 2, f(x) = 0 otherwise. Then the only functions g such that g(X) is independent of f(X), are functions that map all of X to a single value, which does not capture the idea of "subtracting out" f(X). For one thing, one would like to be able to deduce the value of X by observing the values of f(X) and g(X), and that is not possible here.
As a compromise one could instead seek a function g such that if W is the joint distribution of f(X) and g(X), then H(X|W) = 0, and the mutual information I(f(X);g(X)) is minimized. But in general then, f(X) and g(X) would not be independent.
Any help would be appreciated--especially a pointer to other material that deals with "subtracting out" a random variable in a similar manner to this!
let X be a discrete R.V. and let Y = f(X) for some function f. I wish to find a function g, such that Y and Z = g(X) are independent, and also such that the uncertainty H(Z) is maximized. For example, suppose X is uniformly distributed over {0,1,2,3,4,5,6,7} and f(x) = 0 if x < 4, f(x) = 1 otherwise. Then if we let g(x) = x mod 4, g satisfies the requirements in this example. One could interpret Z as the distribution X from which the distribution Y has been "subtracted out." Encoding the values of X in binary as 000,001,010,011,100,101,110,111, we see that f extracts the left bit of X, and g extracts the remaining two bits.
However, this is not always possible; for example suppose X is uniformly distributed over {0,1,2} and f(x) = 1 if x == 2, f(x) = 0 otherwise. Then the only functions g such that g(X) is independent of f(X), are functions that map all of X to a single value, which does not capture the idea of "subtracting out" f(X). For one thing, one would like to be able to deduce the value of X by observing the values of f(X) and g(X), and that is not possible here.
As a compromise one could instead seek a function g such that if W is the joint distribution of f(X) and g(X), then H(X|W) = 0, and the mutual information I(f(X);g(X)) is minimized. But in general then, f(X) and g(X) would not be independent.
Any help would be appreciated--especially a pointer to other material that deals with "subtracting out" a random variable in a similar manner to this!
Last edited: