- #1
Kenneth Mann
- 424
- 3
In the next few insertions, I shall attempt to explain the concept and operation of Karnaugh Maps. I hope this will be of interest to someone. I would welcome your questions and opinions.
Initial Concept
M. Karnaugh published a paper in October 1953, in which he described the basic principles of what has since become known as the ‘Karnaugh Mapping’ technique. In this re-examination of that technique, attempt will be made to explain, as thoroughly as possible, the ideas behind this technology, and to show some ways in which it can be used to simplify the digital logic design function, and to demonstrate some of the exceptional power and flexibility that can be exercised in this graphical mapping method. Hopefully, when finished, this tutorial will provide a basis for facilitating much of the process of designing many of the essential components that are used in digital assemblies.
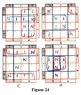
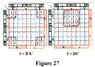
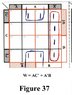
As a start, three attachments are included with this insertion in the string; a set of four-variable K-Maps, a set of six-variable K-Maps, and a 'Truth Table' framework that can be used with maps of up to eight-variables. These can be printed and used whenever needed. In this tutorial, we will show how these are used together. An eight-variable map, and possibly a ten-variable map will be included later.
First, we shall explain the reasoning behind the map, then we shall illustrate its use.
Concept Refinement
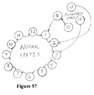
The Karnaugh map, as it was initially envisioned, was considered to be directly capable of minimizing Boolean equations of up to only four variables. To handle a greater number of variables, two or more maps had to be used together, a somewhat cumbersome process - - - and this still entailed a practical working limit of up to approximately six variables. (The process essentially extends the map into three dimensions.)
Then, about a decade after Karnaugh's paper, an individual named Matthew Mahoney observed a symmetrical reflecting approach behind the process of map construction which showed that maps could be extended in design beyond four variables, and from that approach he came up with a slightly different design which, was termed the 'Mahoney Map'. That approach will be shown (in passing) in a future insertion.
KM
Initial Concept
M. Karnaugh published a paper in October 1953, in which he described the basic principles of what has since become known as the ‘Karnaugh Mapping’ technique. In this re-examination of that technique, attempt will be made to explain, as thoroughly as possible, the ideas behind this technology, and to show some ways in which it can be used to simplify the digital logic design function, and to demonstrate some of the exceptional power and flexibility that can be exercised in this graphical mapping method. Hopefully, when finished, this tutorial will provide a basis for facilitating much of the process of designing many of the essential components that are used in digital assemblies.
As a start, three attachments are included with this insertion in the string; a set of four-variable K-Maps, a set of six-variable K-Maps, and a 'Truth Table' framework that can be used with maps of up to eight-variables. These can be printed and used whenever needed. In this tutorial, we will show how these are used together. An eight-variable map, and possibly a ten-variable map will be included later.
First, we shall explain the reasoning behind the map, then we shall illustrate its use.
Concept Refinement
The Karnaugh map, as it was initially envisioned, was considered to be directly capable of minimizing Boolean equations of up to only four variables. To handle a greater number of variables, two or more maps had to be used together, a somewhat cumbersome process - - - and this still entailed a practical working limit of up to approximately six variables. (The process essentially extends the map into three dimensions.)
Then, about a decade after Karnaugh's paper, an individual named Matthew Mahoney observed a symmetrical reflecting approach behind the process of map construction which showed that maps could be extended in design beyond four variables, and from that approach he came up with a slightly different design which, was termed the 'Mahoney Map'. That approach will be shown (in passing) in a future insertion.
KM