Malamala said:
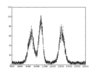
Hello! I have the to fit a curve to the attached data (I plotted it both with and without error bars), where the error bars are Poisson errors i.e. ##\sqrt{N}##, where ##N## is the number of counts in the given bin. I want to fit 3 Gaussians + background and extract the values (and errors associated) of the 3 means and 3 standard deviations.
Usually if someone says they want to fit 3 probability distributions to a set of data, they mean that the data represents the realizations of a single (scalar) random variable. In such a situation, this is a question of modeling one probability distribution as a "mixture" of other probability distributions. There is lots of literature on how to fit mixture distributions to such data.
An example of this type of problem would be:
There are 3 factories, A,B,C that each make widgets.
The weight of a widget made by each factory is a normally distributed random variable.
The normal distributions for the factories may be different.
We have a data consisting of a histogram of widget weights for a months production of the 3 factories. The data gives the weights of 1000 widgets.
The data doesn't not specify which factory made each widget. So, for example, if the data says 40 widgets have a weight between 90.2 and 90.3 kilograms, we don't know how many of these widgets were made in factory A.
Our task is create a probability model that estimates parameters for three normal distributions and the fraction of the 1000 widgets that were chosen from each of these distributions. (We won't be able to say which normal distribution applies to factory A. We only attempt to identify 3 different normal distributions, not to assign each of the distributions to a specific factory.)
The scalar random variable can be defined as "Pick a widget at random from the 1000 widgets and measure its weight".
However, you haven't clearly described your data. Perhaps it does not represent realizations of a single scalar random variable. If it doesn't, you need to explain the data.
Suppose we do an experiment where two marbles collide and smash into a finite number of pieces. On each experiment we record the kinetic energy of each piece. We do 1000 experiments. We combine all this data into a histogram where the x-axis represents kinetic energy and the y-axis represent how many times we observed a piece to have this kinetic energy.
The above situation is
not a histogram of realizations of a single scalar random variable. Each experiment can be regarded as producing a random
vector of results.
In the case of a histogram of data for a single scalar random variable, if we see it's shape looks like 3 gaussian distributions averaged together, it's reasonable to fit a "mixture" model to the data. However, if the histogram comes from random
vectors of data, it isn't so simple to justify fitting a mixture model.

") ) works out an example of a peak on a quadratic background.
) works out an example of a peak on a quadratic background.


 also a bit because it prevents me from plotting the three peaks and thus visualizing my 'exactly the same' claim)
also a bit because it prevents me from plotting the three peaks and thus visualizing my 'exactly the same' claim)