
Is It Possible to Design an Unbreakable Cipher?
Table of Contents
Is it possible to design an unbreakable cipher?
Do methods of encryption exist that guarantee privacy from even the most capable and highly-resourced of prying eyes? This question is especially relevant today, as individual privacy and national security increasingly find themselves at opposite ends of the arbitration table. Powerful nation-states with unparalleled mathematical know-how and prodigious amounts of computing power have been pounding away at modern encryption algorithms for decades, rattling the public’s confidence in the security of today’s most sophisticated ciphers. While this struggle might conjure images of a dismal arms race, there is, in fact, a theoretically secure encryption scheme—the ciphertext it generates is impossible to break even in principle. In 1949, mathematician Claude Shannon proved that a simple cipher, known since the turn of the century, if implemented properly would furnish the user with complete privacy. Shannon called this condition perfect secrecy.
Suppose you intercept the following ciphertext:
[itex]\texttt{aixli tistp isjxl iyrmx ihwxe xiwmr wvhiv xsjsv qeqsv itivj igxyr msriw xefpm}[/itex]
[itex]\texttt{wlnyw xmgim rwyvi hsqiw xmgxv eruym pmxct vszmh ijsvx ligsq qsrhi jirgi tvsqs}[/itex]
[itex]\texttt{xixli kiriv epaip jevie rhwig yvixl ifpiw wmrkw sjpmf ivxcx ssyvw ipziw erhsy}[/itex]
[itex]\texttt{vtswx ivmxc hssvh emrer hiwxe fpmwl xlmwg srwxm xyxms rjsvx liyrm xihwx exiws jeqiv mge}[/itex]
Like any good cryptanalyst worth their salt, you begin by examining the frequency with which the different ciphertext characters appear:
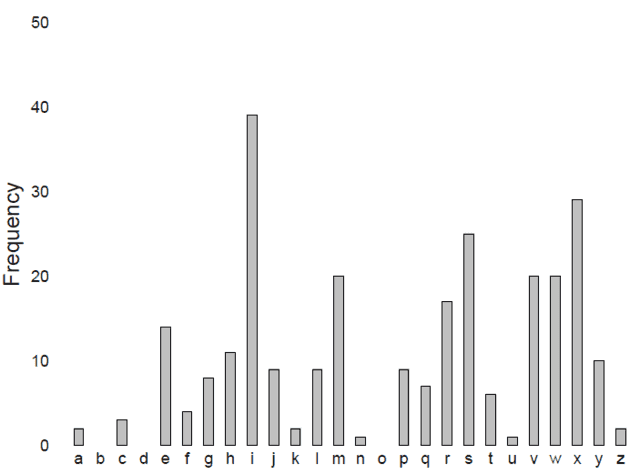
Fig 1. Letter frequencies appear in the above ciphertext.
The resulting distribution is rough: certain letters like [itex]\texttt{i}[/itex], [itex]\texttt{x}[/itex], and [itex]\texttt{s}[/itex] appear notably more often than others. This is characteristic of spoken languages; for example, in English, the five most common letters to appear in the written correspondence are [itex]\texttt{e}[/itex], [itex]\texttt{t}[/itex], [itex]\texttt{a}[/itex], [itex]\texttt{o}[/itex], and [itex]\texttt{i}[/itex]. You take a shot in the dark and suggest that your intercepted communication is a message written in English and that the most common character of the ciphertext is a simple substitution of the most common character of the plaintext language, [itex]\texttt{i} \leftrightarrow \texttt{e}[/itex]: to encrypt the letter [itex]\texttt{e}[/itex], it is shifted by four alphabetic characters to obtain the ciphertext letter [itex]\texttt{i}[/itex]. Next, you surmise that the next most common ciphertext character, [itex]\texttt{x}[/itex], is likewise a simple substitution of some plaintext character, perhaps the next-most common, [itex]\texttt{t}[/itex]. Interestingly, it too is the result of a shift of four. Here, however, your luck runs out: the third-most-common ciphertext letter, [itex]\texttt{s}[/itex], is not a four-letter shift from the third-most-common plaintext letter, [itex]\texttt{a}[/itex]. But wait! It is four away from the fourth most common plaintext letter, [itex]\texttt{o}[/itex]! It is beginning to look quite likely that the ciphertext is a simple shift cipher: each character of the plaintext has been shifted by four letters to generate the ciphertext. The association is of course not perfect, though, since the intercepted ciphertext is but a meager sampling of the English language. Indeed, the smaller the sample, the less we expect character frequencies to match those appropriate to the English language at large.
Though the cryptanalyst’s hunch is correct—the cipher is indeed a simple substitution with a shift of four—it is only a hunch: the cryptanalyst cannot be certain of this conclusion. Instead, the cryptanalyst deals in probabilities and odds ratios, he studies the statistical distributions of ciphertext letters and makes imperfect inferences about the likelihoods of potential plaintext decryptions. Initially, before he gets his hands on any ciphertext, the cryptanalyst’s knowledge of the plaintext message, [itex]M_i[/itex], is minimal. Though the cryptanalyst might consider some messages more likely than others (based on the subject matter of the communication, the structure of the language, the capacity of the channel, and so forth) the a priori probability of any given message, [itex]p(M_i)[/itex], is exceedingly low. Now suppose that this message is encrypted as some ciphertext, [itex]E_i[/itex], and suppose that this ciphertext is intercepted by our cryptanalyst. The probability that the associated plaintext is [itex]M_i[/itex] is now [itex]p(M_i|E_i)[/itex]. This is a conditional probability: given that the ciphertext has been obtained, how is the a priori probability of the message, [itex]p(M_i)[/itex], changed? In general, the acquisition of ciphertext provides at least some information regarding the underlying plaintext; in the case of the shift cipher, it provided enough information to confidently rule out all but one plaintext message1, so that [itex]p(M_i|E_i) \approx 1[/itex].
This concept—that information about [itex]M_i[/itex] is potentially carried by [itex]E_i[/itex]—is central to the design of secure ciphers. For the shift cipher, the frequency statistics of the plaintext are fully retained by the ciphertext: as more and more ciphertext is intercepted, the initially many possible plaintexts converge on an ever-smaller subset as the ciphertext letter frequencies approach those of the plaintext language. This is a general phenomenon: if the ciphertext exhibits any patterns of the plaintext language, gathering more of it will eventually tease them out, driving [itex]p(M_i)[/itex] towards unity. In general, then, we might conclude that [itex]p(M_i)[/itex] is a monotonically increasing function of [itex]n[/itex], the number of intercepted ciphertext characters. But is this always true? Is it inevitable that every cryptosystem exhibits this property, or is it possible to generate a ciphertext such that [itex]P(M_i|E_i)[/itex] never reaches unity, even as [itex]n\rightarrow \infty[/itex]?
Consider the ciphertext with frequency distribution:
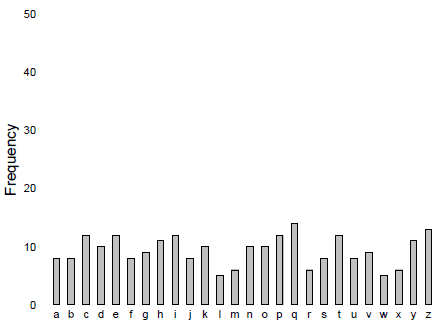
Fig 2. Frequency distribution of some seemingly random ciphertext.
In contrast to Figure 1 for the shift cipher, the frequencies of ciphertext characters are more or less uniformly distributed. It might be suggested that we need more ciphertext: maybe after several hundred more characters, some hint of structure will emerge. But what if Figure 2 summarizes the statistics after collecting an arbitrary amount of ciphertext? Claude Shannon realized that if the ciphertext can be made truly random, then the uniformity of Figure 2 would persist indefinitely. With all features of the plaintext completely masked, the ciphertext is no help to the cryptanalyst, and [itex]p(M_i|E_i) = p(M_i)[/itex][itex]—the ciphertext discloses no information whatsoever about the plaintext. Shannon called this condition perfect secrecy because the cryptanalyst is maximally ignorant about [itex]M_i[/itex]—any plaintext is perfectly fine candidate decryption. In what follows, we will sketch Shannon’s proof that the Vernam system, a substitution cipher with a random, non-repeating key, achieves perfect secrecy. As we’ll see, though, perfect secrecy is difficult to achieve in practice. So, what if instead of all plaintexts being suitable decipherments a cipher exists for which, say, one hundred plaintexts are suitable decipherments? Not perfect, but easier to implement and the cryptanalyst is still unable to single out unique decryption. Shannon called this condition ideal secrecy2—though the ciphertext might disclose some information about the [itex]M_i[/itex], it’s never enough, no matter how much of it the cryptanalyst collects, to reveal a unique decipherment. We’ll discuss this less rarefied class of ciphers too.
Shannon’s chief contribution to cryptology was to understand that the problem of decipherment was fundamentally one of information: specifically, information held by the cryptanalyst about the plaintext, [itex]M_i[/itex]. Our first order of business will therefore be to relate the probabilities of messages to their information content and establish an information-theoretic statement of perfect secrecy.
The least probable is the most informative
Claude Shannon developed many of his ideas on cryptography in parallel with his work on the encoding and transmission of information across communication channels. Shannon recognized that the problem of separating the signal from interfering noise in the communication channel had deep connections with the problem of deciphering an encrypted message. His declassified work on cryptography, Communication Theory of Secrecy Systems [1] is built on many of the information-theoretic concepts developed in his foundational work A Mathematical Theory of Communication [2].
Imagine selecting a message from some language at random: [itex]p_i[/itex] is the probability that the [itex]i^{th}[/itex] character of the alphabet appears in this message. The quantity [itex]-\log_2 p_i[/itex] is the information content of the [itex]i^{th}[/itex] character3. The average information content per character of a language with an N-character alphabet is
\begin{equation}
\label{entropy}
H = -\sum_i^N p_i \log_2 p_i.
\end{equation}
Shannon recognized that the average information content per character gives a measure of the entropy, [itex]H[/itex], of the message space. Just as thermodynamic entropy applies to a volume of gas particles, Shannon’s entropy applies to collections of messages, like languages. The entropy is maximized when all letters appear in the language with equal frequency, [itex]p_i = p[/itex], so that each message is a random assortment of characters. Compare this “language” to English, where certain letters appear more frequently than others: for example, a word selected at random from English is more likely to possess an [itex]\texttt{S}[/itex] than a [itex]\texttt{Z}[/itex]. We are therefore more certain that an [itex]\texttt{S}[/itex] will appear in a randomly selected English word than we are that an [itex]\texttt{S}[/itex] will appear in a language where all letters appear with equal frequency. Evidently, the higher the entropy of the message space, the more uniform the distribution of characters in the language, and so the lower our chances of correctly guessing the identity of a character (or message) drawn randomly from the language4. Simply stated, Shannon’s information entropy implies that the least probable events are the most informative.
Now, the entropy of the space of all possible messages associated with a given ciphertext can be written [itex]H(M|E=E_i)[/itex]. From the definition above, Eq. (\ref{entropy}),
\begin{equation}
H(M|E=E_i) = -\sum_{j}p(M_j|E_i)\log p(M_j|E_i).
\end{equation}
This quantifies the average uncertainty that a cryptanalyst has regarding the possible plaintext decryptions of some intercepted ciphertext, [itex]E_i[/itex]. We’d like to generalize this, though, so that it doesn’t refer to a specific ciphertext; this way, we can apply it to the entire cryptosystem—the complete space of messages and ciphertexts. So let’s average the conditional entropy [itex]H(M|E=E_i)[/itex] over all possible ciphertexts, [itex]E_i[/itex]:
\begin{eqnarray}
H(M|E) &=& \sum_{i}p(E_i)H(M|E=E_i)\nonumber\\
\label{equiv}
&=&-\sum_{ij}p(E_i,M_j)\log p(M_j|E_i).
\end{eqnarray}
This is Shannon’s theoretical secrecy index, the equivocation5 of the message (we can also talk about the equivocation of the key, by summing over all possible keys, [itex]K_k[/itex], in Eq. (\ref{equiv}).) It formalizes the average degree of uncertainty, or ambiguity, regarding the plaintext associated with ciphertext generated by the cryptosystem. We can take Eq. (\ref{equiv}) a little further and write,
\begin{eqnarray}
H(M|E) &=& -\sum_{ij}p(E_i,M_j)\left[\log p(M_j) + \log \frac{p(E_i,M_j)}{p(E_i)p(M_j)}\right] \nonumber \\
\label{equiv2}
&=& H(M) – I(E;M),
\end{eqnarray}
where [itex]I(E;M) = \sum_{i,j}p(E_i,M_j) \log p(E_i,M_j)/p(E_i)p(M_j)[/itex] is the mutual information of plaintext and ciphertext, which is a measure of the amount of information obtained about the plaintext from the ciphertext. Eq. (\ref{equiv2}) succinctly summarizes the information-theoretic view of decipherment: the uncertainty about the plaintext is reduced from our initial, broad uncertainty constrained only by knowledge of the language ([itex]H(M)[/itex]) through information gleaned from the ciphertext ([itex]I(E;M)[/itex]).
It’s useful to consider the equivocation as a function of [itex]n[/itex], the number of characters of ciphertext received by the cryptanalyst. If the ciphertext does not completely conceal plaintext characteristics, we expect the equivocation to be a decreasing function of [itex]n[/itex] (at least when [itex]n[/itex] isn’t too small) because as the ciphertext grows in length, any regularities and patterns become increasingly apparent and the cryptanalyst grows more and more certain of the range of possible plaintexts. If the ciphertext eventually reveals all of the characteristics of the plaintext language so that [itex]I(E;M) = H(M)[/itex], the equivocation drops to zero and only one plaintext decryption remains. Shannon called the number of ciphertext characters necessary for unique decryption the unicity distance, [itex]U[/itex]. In Figure 3, the message and key equivocations of the simple substitution cipher, in which each plaintext character is encrypted as a unique ciphertext character, are shown6:
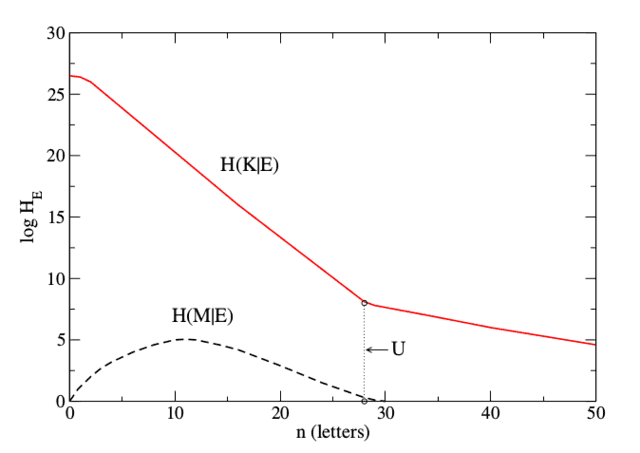
Fig 3. Equivocation of English-language message, [itex]H(M|E)[/itex], and key, [itex]H(K|E)[/itex], as a function of the number of letters, [itex]n[/itex], in the intercepted ciphertext for a simple substitution cipher. The unicity distance, [itex]U[/itex], is marked. This figure is based on a recreation of Fig. 9 in [1].
Interestingly, the two equivocations do not go to zero at the same number of intercepted letters: after all, once you’ve got the plaintext, haven’t you got the key? Not necessarily—if the intercepted ciphertext does not include at least one instance of each unique ciphertext character, then the cryptanalyst will have no way of knowing, even in principle, which plaintext characters they map to and so won’t recover the full key7. This is necessarily true of any English ciphertext with fewer than 26 characters, and as Figure 3 shows, only after [itex]n=50[/itex] characters on average does an English message include instances of all 26 letters of the alphabet. Meanwhile, the message equivocation goes to zero at around [itex]n=30[/itex], since the cryptanalyst can recover the message without obtaining the full key. Just like our opening example with the shift cipher, once a few letters have been worked out, the structure of the language does the rest the constrain the range of possible messages.
At the opposite end of the spectrum from unique decipherment, [itex]H(M|E) = 0[/itex], perfect secrecy ensures that the ciphertext provides zero information about the plaintext, [itex]I(E;M)=0[/itex], and the cryptanalyst is kept in a persistent state of maximal confusion, since [itex]H(M|E) = H(M)[/itex] is constant. Shannon clearly demonstrated the requirements of the perfect cipher via a simple figure:
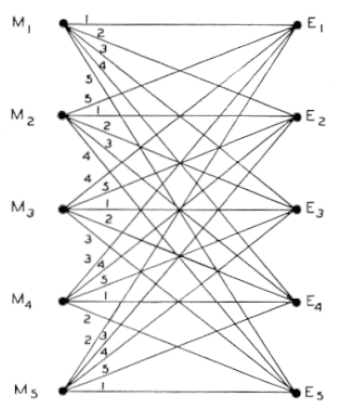
Fig 4. The perfect cipher has at least as many keys as messages. Figure from [1].
As long as the number of keys is at least as great as the number of messages, any given ciphertext has a valid decryption to any plaintext. More generally, the entropy of the keyspace must be at least as great as that of the message space, [itex]H(K) \geq H(M)[/itex], so that whatever information is gained about possible plaintext decryptions is compensated for by the uncertainty over the possible keys.
The polyalphabetic substitution cipher known as the Vernam system achieves perfect secrecy by employing a random key as long as the message. The keyspace includes all meaningful English messages, like “[itex]\texttt{Obviously, you’re not a golfer}[/itex]”, as well as all meaningless messages, like any of the effectively infinite number of garbled strings of letters, and so easily satisfies [itex]H(K) > H(M)[/itex]. In modern implementations, the Vernam cipher combines a random binary keystream with decoded bits of plaintext using the logical bitwise operation exclusive or, or XOR, which works like [itex]1+0=0+1 = 1[/itex] and [itex]0+0 = 1+1 = 0[/itex]. The XOR operation transfers the randomness of the key to the plaintext to create a random ciphertext. Figure 5 illustrates this phenomenon, which occurs when the character sets and lengths of the key and plaintext are the same:
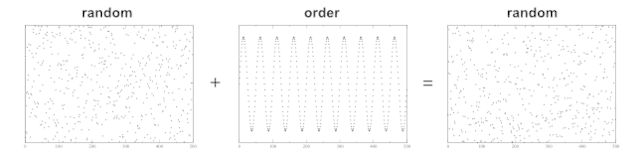 Fig 5. 500 floating point numbers selected uniformly between the range [0,10] added [itex]\mod 10[/itex] to a [itex]sin[/itex] function on the same domain returns another uniform random distribution of floating points. The analogy is random key + “ordered” plaintext yields a random ciphertext.
Fig 5. 500 floating point numbers selected uniformly between the range [0,10] added [itex]\mod 10[/itex] to a [itex]sin[/itex] function on the same domain returns another uniform random distribution of floating points. The analogy is random key + “ordered” plaintext yields a random ciphertext.
Because the ciphertext is random, it is statistically independent of the plaintext, so that [itex]p(M_i|E_j)=p(M_i)[/itex] and
\begin{equation}
I(E;M) \propto \log\frac{p(E_i,M_j)}{p(E_i)p(M_j)} = \log 1 = 0.
\end{equation}
Perfect secrecy is thereby assured. As an example, here is some ciphertext that nobody—not Alan Turing, not the NSA—nobody, can break:
[itex]\texttt{asxle tiytp imjxl oyrmf ihwue xjwmr kvhiv bwjnv qeqsv itivj igxyr mkriw xefpm}[/itex]
[itex]\texttt{wlnyw lmgim rwyvp hsqiw xmgev eruym pmect vdzmh qjsvp lqgsq gsrhi jhrgi tvsqs}[/itex]
The Vernam cipher has historically found widespread use, most noticeably during the Cold War: Soviet spies employed a version of the Vernam cipher using pre-deployed keys scrawled on notepads, earning this cryptosystem the moniker one-time pad. Likely due to the logistical difficulties of keeping unused, cryptographic-grade random keys around, the Soviets eventually re-used some of their key material under the watchful eyes of U.S. and British signals intelligence, enabling some of their communications to be broken. Generating long, truly random keys is also hard: pseudo-random number generators, regardless of quality, churn out deterministic key streams that can in principle be broken. Natural sources of unbiased, independent bits, like noise from electronic circuits or radioactive decays, are ideal but generally not readily (or safely) available in sufficient supply to encrypt arbitrarily long messages, hence the modern proliferation of theoretically insecure but much more practical encryption methods like block ciphers.
Given the obstacles to achieving perfect secrecy in practice, let’s back away from the hard requirement that [itex]H(M|E) = H(M)[/itex] and examine instead the conditions under which ideal secrecy is attained. Here, though [itex]H(M|E)[/itex] is a decreasing function of [itex]n[/itex], the unicity distance is never reached: [itex]U > n[/itex]. This is our new requirement.
[itex]1 < H(M|E) < H(M)[/itex]: not perfect, but it should do
To understand the general characteristics of ciphers that exhibit ideal secrecy, we will compute the unicity distance of a model cipher called the random cipher [1,5]. The random cipher works as follows: given a ciphertext, [itex]E_i[/itex], and key, [itex]K_k[/itex], the ciphertext decrypts to some message, [itex]M_j[/itex], uniformly distributed across the space of all messages. Since [itex]M_j[/itex] is not determined uniquely by the pair [itex](E_i,K_k)[/itex], the random cipher is a whole ensemble of ciphers. This means we can apply statistics to the ensemble to model the unicity distance of a general cipher.
First, let’s examine the message space. We mentioned earlier that there are many more meaningless than meaningful messages in English8. Formally, if there are [itex]N[/itex] letters in a particular alphabet, then there are [itex]N^{L} = 2^{R_0L}[/itex] different [itex]L[/itex]-letter sequences possible, where [itex]R_0= \log_2 N[/itex]. The quantity [itex]R_0[/itex] is the entropy per letter of the “language” where each character has the same probability of occurrence, [itex]p=1/N[/itex]. Entropy is maximized for such a language. Meanwhile, of all possible messages, a smaller number [itex]2^{RL}[/itex] will be meaningful in English, where [itex]R[/itex] is the entropy per letter, [itex]H(M)/L[/itex], of English. Because the letters in this restricted space of meaningful English sentences do not appear with equal probability, [itex]R[/itex] is smaller than [itex]R_0[/itex]: with [itex]N = 26[/itex], we find [itex]R_0 =4.7[/itex] bits/letter, whereas [itex]R[/itex] is estimated to be around only [itex]2.6[/itex] bits/letter for 8-letter chunks of English, and [itex]1.3[/itex] bits/letter for more sizable chunks. [itex]R[/itex] is smaller than [itex]R_0[/itex] because the distribution of letters in English words is not random: per letter, there is less information on average in English.
A useful quantity is a redundancy of the language, [itex]D = R_0 – R[/itex]: it is the maximum amount of information possible per character minus the actual amount of information so contained. For English, [itex]D = 2.1[/itex] for eight-letter words, meaning that around half of the letters in an eight-letter word of English word are superfluous, i.e. they are fixed by the structure of the language. For example, the letter [itex]\texttt{q}[/itex] is always followed by the letter [itex]\texttt{u}[/itex], and there must usually not be any more than three consonants in a row. If you’ve ever done one of those exercises where the vowels are removed from a typical English message and you find yourself still able to read it—that’s redundancy. It is relevant to data compression, which exploits regularities and patterns of language to maximize the information content per letter9. Anyway, it’s clear that the more redundant the language, the smaller the proportion of meaningful to meaningless messages. With these ideas in mind, consider the basic cryptosystem:
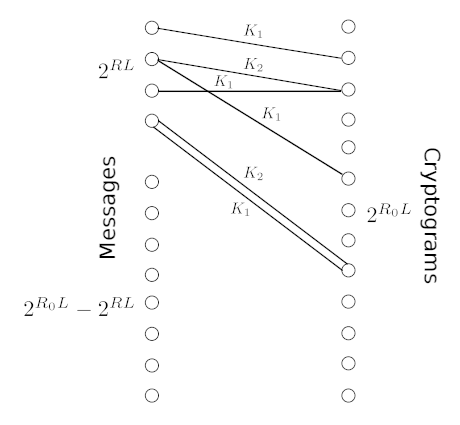
Fig 6. Schematic of a simple cryptosystem. Plaintext messages form the column on the left: the top group of [itex]2^{RL}[/itex] messages are meaningful; the bottom group of [itex]2^{R_0L}-2^{RL}[/itex] are meaningless. Two different keys connect the meaningful messages to the space of all possible cryptograms. The random cipher is an ensemble of such cryptosystems, each with a different mapping between messages and cryptograms. Figure adapted from Fig. 4 in [5].
Suppose a cryptanalyst has intercepted $n$ letters of an $L$-letter cryptogram. Figure 6 illustrates his situation vis-a-vis possible decryptions and keys. Of all possible plaintexts, we assume only meaningful messages, of which there are [itex]2^{RL}[/itex], are possible decryptions. Meanwhile, the ciphertext can take the form of any message, meaningful or not. There are more of these, [itex]2^{R_0 L} > 2^{RL}[/itex]. Each plaintext message generally encrypts via different keys, of which there are [itex]2^{H(K)}[/itex], to different ciphertexts so that we have a one-to-many system. It is also possible that a given ciphertext decrypts via different keys into different meaningful messages. In other words, we might also have a many-to-one system—a situation known as a spurious message decipherment resulting in a nonzero message equivocation. For example, the cryptogram [itex]\texttt{WNAJW}[/itex] decrypts to [itex]\texttt{RIVER}[/itex] via a shift of 5 or [itex]\texttt{ARENA}[/itex] via a shift of 22. If this is the situation after the full cryptogram has been intercepted, [itex]n=L[/itex], then [itex]U>L[/itex] and the unicity distance lies beyond the size of the ciphertext, and unique meaningful decryption will be impossible.
While this is how we defined ideal secrecy, this isn’t the criterion we’ll use to explore it because determining the conditions under which spurious message decipherment occurs for the random cipher is hard. So rather than defining the unicity distance to be the number of intercepted letters needed to recover a unique message, we’ll identify it with the number of letters needed to recover a unique key, [itex]U_K[/itex]. If [itex]U_K > n[/itex], then the cryptanalyst is unable to recover a unique key and is in a situation analogous to spurious message decipherment, called spurious key decipherment. Note, though, that in general [itex]U_K > U[/itex] as we saw for the simple substitution cipher in Figure 3, and so the criteria we’ll determine for ideal secrecy will still be relevant if a little on the conservative side. Therefore, in what follows, we’ll drop the subscript.
If the unicity distance can be made arbitrarily large so that [itex]n<U[/itex] generally, the cryptanalyst will always find himself in the situation of Figure 6. The best way to force a spurious key decipherment is to dump lots and lots of keys into the pot. In other words, the larger the entropy of the keyspace, [itex]H(K)[/itex], the more keys there are; this makes it harder to find the key, making spurious key decipherment more likely for a given amount, [itex]n[/itex], of intercepted ciphertext. And so [itex]U[/itex] grows with increasing [itex]H(K)[/itex]. On the other hand, we assume that each of these keys yields a decipherment to any of the [itex]2^{R_0L}[/itex] possible messages chosen at random; only a number [itex]2^{RL}[/itex] of which are meaningful. So, the smaller the proportion of meaningful messages the less likely that a particular key will “land” you in the space of meaningful messages, where your decipherment is presumed to exist. A relatively small number of meaningful messages, then, makes it harder for there to be multiple keys yielding the same meaningful plaintext and hence lowers [itex]U[/itex].
To summarize, two factors affect the unicity distance in opposite ways: the size of the key space (quantified in terms of [itex]H(K)[/itex]), which is a property of the cryptosystem, acts to increase [itex]U[/itex], and redundancy (coming into play as the proportion of meaningful messages, [itex]2^{RL}/2^{R_0L} = 2^{-LD}[/itex]), which is a property of the language, acts to decrease [itex]U[/itex]. Note that these are essentially the two terms in Eq. (\ref{equiv2}) determining the equivocation: [itex]I(E;M)[/itex] is largely determined by [itex]H(K)[/itex], and [itex]H(M)[/itex] is summarized by [itex]D[/itex], the redundancy.
Putting these factors together, we can easily determine the expected number of spurious key decipherments, [itex]\langle n_K \rangle[/itex], under the assumption of our random cipher. The number of spurious keys should depend on the number of total keys and the relative number of meaningful messages. Specifically, assuming that there is one correct meaningful solution with key [itex]K_j[/itex], [itex]\langle n_K \rangle = (2^{H(K)} -1)p[/itex], where [itex]p[/itex] is the probability that any of the remaining [itex]2^{H(K)} -1[/itex] keys map to the same plaintext. What’s this probability? For the random cipher, it’s just [itex]2^{RL}/2^{R_0L} = 2^{-LD}[/itex]—the chance that we land on a particular meaningful message! So we have then,
\begin{eqnarray}
\langle n_K \rangle = (2^{H(K)} -1)2^{-nD} &\approx& 2^{H(K)-nD},\\
&\approx& 2^{D\left(\frac{H(K)}{D}-n\right)}.
\end{eqnarray}
When the quantity [itex]H(K)/D = n[/itex], we have that [itex]\langle n_K \rangle = 1[/itex]. This is the unicity distance,10
\begin{equation}
U = \frac{H(K)}{D}.
\end{equation}
For a ciphertext with [itex]L[/itex]-letters, we can write
\begin{equation}
U = L\left[\frac{H(K)}{H_0 – H(M)}\right]
\end{equation}
where [itex]H_0 = LR_0[/itex] is the entropy of the full (meaningful and meaningless) message space. For perfect secrecy where the key is random, [itex]H(K) = H_0[/itex], [itex]U > L[/itex] as long as the entropy of the language [itex]H(M) < H_0[/itex]. While no extant language has such a monstrous property, it’s possible to approach this limit using data compression techniques. Source coding, or ideal compression, reduces the redundancy of any message to zero, resulting in a randomized string. If we apply encryption to this compressed message, we can increase the unicity distance over-application of the same encryption to the original, uncompressed message. For this reason, many modern ciphers employ some sort of compression before encryption; however, they are not perfect because such ideal compression simply does not exist for spoken languages. For ideal secrecy, [itex]H(K) \leq H_0[/itex], and so we can’t draw any general conclusions without making assumptions about the entropy of the language, [itex]H(M)[/itex]. For English, [itex]H(M)/H_0 = R/R_0 = 1.3/4.7 = 0.27[/itex] and so \begin{equation} U = 1.37 \times L \frac{H(K)}{H_0}, \end{equation} with the requirement that [itex]H(K) > 0.73H_0[/itex] in order to ensure that [itex]U > L[/itex]. Interestingly, this amount of entropy per character is achieved with a random 11-character alphabet, since [itex]0.73H_0 = \log 26^{0.73} \approx \log 11[/itex]—less than half the size of the randomized alphabet needed for perfect secrecy. Of course, the whole point of considering the more general class of ideal ciphers was to avoid the need for long, high-quality random keystreams. The lower entropy keyspace needed for ideal secrecy is provided by certain cryptographically secure pseudo-random number generators, meaning that only the initial seed data needs to be shared between sender and receiver. Ideal secrecy, it turns out, is practically achievable.
References and Footnotes
[1] Shannon, C. E., Communication Theory of Secrecy Systems. Bell System Technical Journal, 28 (1949).
[2] Shannon, C. E., A Mathematical Theory of Communication. Bell System Technical Journal, 27 (1948).
[3] Wyner, A. D., The wire-tap channel. Bell System Technical Journal, (1975).
[4] Blom, R. J., Bounds on Key Equivocation for Simple Substitution Ciphers. IEEE Transactions on Information Theory, IT-25 (1979).
[5] Hellman, M. E., An Extension of the Shannon Theory Approach to Cryptography. IEEE Transactions on Information Theory, IT-23 (1977).
1If you’re not convinced, note that with only three plaintext characters cracked, the first three plaintext words are: [itex]\texttt{_e t_e _eo__e}[/itex]. These are the first three words in a most famous political document. Can you figure it out? back
2Apparently, the words ideal and perfect aren’t synonyms in cryptology circles. back
3For example, “heads” in a coin toss convey 1 bit of information, since [itex]p_i = 1/2[/itex]. back
4Yes, Shannon’s conception of information content has the perhaps non-intuitive property that truly random messages are the most informative. This definition is evidently not concerned with the semantics or meaning, of the message. back
5This term I believe was first used by information theorist Aaron Wyner and defined by him “as a measure of the degree to which the wire-tapper is confused”; see [3]. For Shannon, this quantity arose out of the study of communication over discrete channels with noise: as a stream of bits is sent across a channel, the effect of noise is to randomly flip some of the bits. The task of the receiver is to reconstruct the original message from that received: the equivocation is an indication of the ambiguity of the received signal. See [2]. back
6This is a difficult quantity to study because the equivocation Eq. (\ref{equiv}) is challenging to calculate for most practical ciphers. For the simple substitution cipher, the key equivocation for a message of length [itex]L[/itex] is
\begin{equation}
\label{footn1}
H(K|E) = -\sum_{i=1}^{N!} \sum_{j} p(K_i)p(E_j)\log\left(\frac{\sum_{k}^{N!}p(E_j,K_k)}{p(K_i)}\right)
\end{equation}
where the sum over [itex]j[/itex] includes all cryptograms of length [itex]L[/itex]. If [itex]{\bf x} = (x_1,x_2,\cdots,x_N)[/itex] is a vector containing the frequencies of the different characters in the plaintext, then the frequencies of the ciphertext characters are just permutations of this vector: [itex]x_n = y_{t_i(n)}[/itex], where the [itex]t_i[/itex] is the cipher transformations with key [itex]K_i[/itex], [itex]M_k = t^{-1}_i E_j[/itex]. For the terms in Eq. (\ref{footn1}) we have [itex]p(E_j) = p(t^{-1}_i E_j)=p(M_k)[/itex]. Yes, I know that’s a weird way to write it but think about it. For simple substitution, the a priori chance that we obtain a certain ciphertext, [itex]E_j[/itex] is the same as having selected a certain message, [itex]M_k[/itex], at least as far as language statistics is concerned. Then, if [itex]q_n[/itex] is the probability of occurrence of the [itex]n^{th}[/itex] character, [itex]p(E_j) = q_1^{x_1}q_2^{x_2}\cdots q_N^{x_N}[/itex]. Next, the prior probability of the key is just [itex]p(K_i) = 1/N![/itex] because there are [itex]N![/itex] different keys (the number of ways one can order the alphabet of [itex]N[/itex] letters) all equally probable. With these clarifications, the equivocation can be written [4]
\begin{equation}
\label{foot2n}
\sum_{|x|=L}\frac{L!}{x_1!x_2!\cdots x_N!}\prod_{n=1}^{N}q_n^{x_n}\log \frac{\sum_{l=1}^{N!}\prod_{n=1}^N q_{n}^{y_{t_{i}(n)}}}{\prod_{n=1}^Nq_n^{x_n}}.
\end{equation}
Here we’ve replaced the notation [itex]\sum_j[/itex] in Eq. (\ref{footn1}) and the verbal caveat that the sum is to include all cryptograms of length [itex]L[/itex] with the sum [itex]\sum_{|x| = L}[/itex]. The constraint [itex]|x| = \sum_{n=1}^N x_i = L[/itex] concerns the frequencies of the characters, but not their ordering. That’s what the term [itex]L!/x_1!x_2!\cdots x_N![/itex] is for: it takes care of enumerating all of the unique words with the given frequencies [itex]{\bf x}[/itex], but we’ll have more to say about this in a moment. Evaluating Eq. (\ref{foot2n}) is hard: the probabilities [itex]q_n[/itex] depend on the length of a word: it’s entirely possible that you’re generally more likely to find more [itex]\texttt{p}[/itex]’s in ten-letter samples of English than four, and it is true of uncommon letters like [itex]\texttt{z}[/itex]. This makes it hard to evaluate Eq. (\ref{foot2n}) because these n-gram frequencies are hard to come by—someone needs to have worked them out. While these data exist for small groupings and large groupings the statistics of English at large apply, it’s the intermediate-length groupings that are difficult to handle. Eq. (\ref{foot2n}) is also a long sum, and that can be technically challenging! It’s an interesting sum, though, too. Of words of length [itex]L[/itex], we can have words of all the same letter (with [itex]L!/L! =1[/itex] combination) or 1 of one letter and [itex]L-1[/itex] of another (with [itex]L!/1!(L-1)![/itex]), or 2 of one letter and [itex]L-2[/itex] of another (with [itex]L!/2!(L-2)![/itex] combinations), and so on. Or, we can have 1 of one letter, 1 of another, and [itex]L-2[/itex] of another (with [itex]L!/1!1!(L-2)![/itex] combinations). While Eq. (\ref{foot2n}) tells us to perform the sum in this way, it’s up to us to enumerate all of these possibilities. The number of possibilities depends on [itex]L[/itex] especially: the terms in the denominators of the sum of the combination to [itex]L[/itex], and so the series sum is over all such possibilities. These are called the partition numbers of [itex]L[/itex], and the first few go like 1, 2, 3, 5, 7, 11, 15, 22, 30, 42,… These numbers tell you how many distinct terms [itex]L!/x_1!x_2!\cdots x_N![/itex] you have; and for each one there are [itex]N \choose \ell[/itex] copies for the [itex]\ell[/itex] letters represented (the number of nonzero [itex]x_n[/itex].) back
7 This is a result of the fact that the cryptanalyst has only a single ciphertext to work with—it’s the one he intercepted and was not of his choosing. This is called a known ciphertext attack as opposed to a chosen ciphertext attack, in which the cryptanalyst can perform his encryptions with the unknown key. back
8 If this wasn’t true, cryptography wouldn’t work quite the same way. Consider a language in which every possible string of characters was a “meaningful” message. Then, even the ciphertext, which is supposed to be a random string of nonsense, would itself be a meaningful message in the language—as would every possible decryption! back
9James Joyce’s novel Finnegans Wake, with its improvised vocabulary and extravagant prose, is notably less compressible than other English novels. back
10We obtained this result using the key equivocation and the condition of spurious key decipherment. This is because the alternative approach—considering the message equivocation and associated spurious message decipherment—is much more difficult. That said, the average number of spurious message decipherments, [itex]\langle n_M \rangle[/itex], must satisfy [itex]\langle n_M \rangle \leq \langle n_K \rangle[/itex]. This is because there are at least as many keys as meaningful messages, and generally, many more of the former (because the keys can be anything, meaningful or otherwise) and so the unicity distance derived above applies to the message equivocation as well. back
After a brief stint as a cosmologist, I wound up at the interface of data science and cybersecurity, thinking about ways of applying machine learning and big data analytics to detect cyber attacks. I still enjoy thinking and learning about the universe, and Physics Forums has been a great way to stay engaged. I like to read and write about science, computers, and sometimes, against my better judgment, philosophy. I like beer, cats, books, and one spectacular woman who puts up with my tomfoolery.

“That’s generally true, except when you have a provably secure encryption scheme. There is only one such scheme—the Vernam system. If the key is truly random, the Vernam cipher is theoretically unbreakable, as I hoped to demonstrate in this article.”
The Vernam cipher has perfect secrecy — disclosure of the ciphertext alone does not give the attacker any information about the message. However, secrecy is not the only goal in security. For instance, one might want immunity from message forgery.
The classic example is an attacker who knows the plaintext and can modify “Attack at dawn” to “Attack at dusk” without knowledge of the key.
“A good appraisal.
But after such a confident appraisal of “unbreakable” cryptographic systems I feel the need to point out that it is all too easy to be fixated and blinded by the theoretical security of your favourite cryptographic algorithm. The clear understanding your algorithm prevents you seeing the alternative openings that may be exploited by an enemy. The belief that you have a secure algorithm is also a liability because it distracts you from the greater weakness of the surrounding security structure.
Game theory rules the day, paranoia the night.[/quote]That’s generally true, except when you have a provably secure encryption scheme. There is only one such scheme—the Vernam system. If the key is truly random, the Vernam cipher is theoretically unbreakable, as I hoped to demonstrate in this article.
A good appraisal.
But after such a confident appraisal of “unbreakable” cryptographic systems I feel the need to point out that it is all too easy to be fixated and blinded by the theoretical security of your favourite cryptographic algorithm. The clear understanding your algorithm prevents you seeing the alternative openings that may be exploited by an enemy. The belief that you have a secure algorithm is also a liability because it distracts you from the greater weakness of the surrounding security structure.
Game theory rules the day, paranoia the night.
I can’t say I understand all the math that well, but it was interesting read!
Excellent!
Shannon’s entropy model is used in a lot of disparate fields.
Ecology: Species diversity can be defined precisely as you described H, Shannon’s entropy. If we limit an example to tree species: Boreal and montane systems have low diversity of tree species, cloud forest systems have very high diversity of tree species – such that you often have less than one individual of a given species per hectare. Abusing your nice model, it appears cloud forest species diversity would equate to a sample of glyphs from a language with thousands of “letters”. If you mix in all of the species: trees, shrubs, epiphytes, invertebrates, vertebrates, Eukaryotes on down to single-celled Prokaryotes, etc., you easily have a language with an absurd number of “letters”. No wonder we don’t fully understand tropical systems.
Your explanation is far better than the one I used for years to help students to understand Shannon’s entropy. Darn it all….
Superb Insight!
That's generally true, except when you have a provably secure encryption scheme. There is only one such scheme—the Vernam system. If the key is truly random, the Vernam cipher is theoretically unbreakable, as demonstrated in this article.
A good appraisal. But after such a confident appraisal of “unbreakable” cryptographic systems I feel the need to point out that it is all too easy to be fixated and blinded by the theoretical security of your favourite cryptographic algorithm. The clear understanding your algorithm prevents you seeing the alternative openings that may be exploited by an enemy. The belief that you have a secure algorithm is also a liability because it distracts you from the greater weakness of the surrounding security structure. Game theory rules the day, paranoia the night.
I can't say I understand all the math that well, but it was interesting read!
Superb Insight!