
The Monographic Substitution Cipher: From Julius Caesar to the KGB
A monographic substitution cipher works by replacing individual characters of plaintext with corresponding characters of ciphertext. It is perhaps the simplest encryption scheme ever devised: early monographic substitution ciphers were employed by Julius Caesar to secure private correspondence. These ciphers were low-tech, required virtually no mathematics, and encryption and decryption could be accomplished by finger counting. Perhaps surprisingly, then, the most secure modern cipher also happens to be a monographic substitution cipher, demonstrating the important cryptographic lesson that simplicity does not imply triviality. In this article, we’ll study the monographic substitution cipher concept by examining several of its varied implementations, from the ancient to the state-of-the-art.
Table of Contents
Shift cipher
Consider a simple cipher in which a single substitution rule is applied: each character of plaintext, [itex]p[/itex], is replaced by the ciphertext character, [itex]c[/itex], located [itex]m[/itex] steps further ahead in the alphabet than [itex]p[/itex]. For a plaintext letter located towards the end of the alphabet, if the number of steps [itex]m[/itex] exceeds the number of remaining letters in the alphabet, the rule is to wrap around to the beginning. Mathematically, this operation is known as modular arithmetic, and we write [itex]c = (p + m)\,{\rm mod}\,N[/itex], where here the values of [itex]c[/itex] and [itex]p[/itex] are not the characters themselves but numerical representations (for example, in the English alphabet we’d denote the letters [itex]\texttt{A-Z}[/itex] by the numbers 0-25.), and where [itex]N[/itex] is the number of letters in the alphabet. Expressions of the form [itex]a=b\,{\rm mod}\,n[/itex] are called congruences and read “[itex]a[/itex] is congruent to [itex]b[/itex] modulo [itex]n[/itex].” The mod operation gives the remainder, [itex]a[/itex], when [itex]b[/itex] is divided by [itex]n[/itex]. You can think of modular arithmetic as analogous to time on a clock, but with the [itex]n[/itex] letters in place of the hours: once you count past the [itex]n^{th}[/itex], you start over at the [itex]1^{st}[/itex]. Thinking in this way, the cipher can be represented by two concentric circles of characters: the outer one representing the plaintext and the inner the corresponding ciphertext:
 Fig 1. Representation of the shift cipher as two concentric rings: the outer is the plaintext and the inner, the corresponding ciphertext. For an alphabet with [itex]N[/itex] characters, there are [itex]N-1[/itex] implementations of this cipher.
Fig 1. Representation of the shift cipher as two concentric rings: the outer is the plaintext and the inner, the corresponding ciphertext. For an alphabet with [itex]N[/itex] characters, there are [itex]N-1[/itex] implementations of this cipher.
For this reason, the shift imparted by the cipher is sometimes called a rotation. Hence the name shift (or rotation) cipher. It’s also called a Caesar cipher, after Julius Caesar who used the cipher with a shift of 3 to conceal military secrets. Consider the following plaintext:
[itex]\texttt{We hold these truths to be self-evident, that all men are created equal,}[/itex]
[itex]\texttt{that they are endowed by their Creator with certain unalienable Rights,}[/itex]
[itex]\texttt{that among these are Life, Liberty, and the Pursuit of Happiness.}[/itex]
Application of the shift cipher with [itex]m=5[/itex] gives
[itex]\texttt{bjmtq iymjx jywzy mxytg jxjqk janij syymf yfqqr jfsfw jhwjf yjijv zfqym}[/itex]
[itex]\texttt{fyymj dfwjj sitbj igdym jnwhw jfytw bnymh jwyfn szsfq njsfg qjwnl myxym}[/itex]
[itex]\texttt{fyfrt slymj xjfwj qnkjq ngjwy dfsiy mjuzw xznyt kmfuu nsjxx}[/itex]
where the punctuation has been dropped and only the letters have been encrypted (but we’ll soon enlarge the alphabet to include punctuation.) You can see that I’ve grouped the ciphertext into “words” of five letters each; this is arbitrary but it’s done to homogenize the sentence structure. The English language is characterized by certain regularities—its syntax and grammar—that give it an identifiable statistical structure. For example, the letter [itex]\texttt{S}[/itex] occurs more frequently than the letter [itex]\texttt{Z}[/itex]; the combination, [itex]\texttt{TH}[/itex], occurs more often than [itex]\texttt{RB}[/itex]. The letter [itex]\texttt{E}[/itex] occurs at the end of words more than any other letter, while [itex]\texttt{T}[/itex] holds this distinction for the beginning words. The word [itex]\texttt{THE}[/itex] is the most common three-letter word, whereas the word [itex]\texttt{RUG}[/itex] occurs much less frequently. The grouping into five-letter “words” effectively erases any regularities based on words—we don’t know where words begin or end, or how long they are, but it does nothing to hide the relative frequencies of the letters. And this is bad.
If we count the prevalence of letters in our ciphertext, we find that [itex]\texttt{J}[/itex] occurs most frequently (22 times), followed by the letter [itex]\texttt{Y}[/itex] (18 times). According to frequency analysis of letters in English, the most common letters are [itex]\texttt{E, T, A, O, I,}[/itex] and [itex]\texttt{N}[/itex], whereas the least common are [itex]\texttt{J, X, Q,}[/itex] and [itex]\texttt{Z}[/itex]. As an initial guess, then, a cryptanalyst intent on breaking this cipher might suppose that [itex]\texttt{J}[/itex] codes for [itex]\texttt{E}[/itex], and [itex]\texttt{Y}[/itex] for [itex]\texttt{T}[/itex] (and he’d be right—even though our selection is only one sentence (and a very famous one at that), its two most common letters agree with the statistics of English at large.) Continuing in this manner, depending on the length of the ciphertext, he will succeed in cracking at least a few letters. He doesn’t need to break the whole ciphertext this way—once he’s convinced himself that he’s gotten even one letter correct, he can recover the shift amount, [itex]m[/itex]. This number is the key of the shift cipher and must be kept secret—once the cryptanalyst has it, he can recover the entire plaintext.
So we’ve seen how the inherent regularities and patterns of the English language can be leveraged by a cryptanalyst to break the code, and a good cryptosystem must do its best to obscure them. As advocated by Claude Shannon as early as 1949, the security of a cryptosystem is based on the properties of confusion and diffusion [1]: confusion means that the ciphertext depends in a very complex way on the plaintext and key; diffusion means that the statistics of the plaintext is spread out and diluted in the statistics of the ciphertext1. The shift cipher does nothing to diffuse the statistics of the English plaintext, and so it’s easy to break.
It’s worth noting that the shift cipher works with any alphabet: English letters, binary, whatever. The binary alphabet [itex]\{0,1\}[/itex] is interesting: if [itex]m[/itex] is divisible by [itex]2[/itex], then the cipher acts as the identity on the plaintext and nothing gets encrypted. If [itex]m[/itex] is chosen to be odd, something different happens. Suppose we have an English language plaintext, and we wish to encrypt it using the shift cipher based on the binary alphabet. We first translate the English text to binary according to the ASCII2 conversion. Application of the shift cipher, with [itex]m[/itex] odd, flips each bit—it effectively XOR’s the plaintext binary with a string of [itex]1[/itex]’s—a simple modification3. But when we then convert back to ASCII, we find that our plaintext has been scrambled in a seemingly random way:
[itex]\texttt{NOT ON THE RUG, MAN.}[/itex]
translate to binary:
[itex]\texttt{1001110 1001111 1010100 1001111 1001110 1010100 1001000}[/itex]
[itex]\texttt{1000101 1010010 1010101 1000111 1001101 1000001 1001110}[/itex]
rotate by one bit:
[itex]\texttt{0110001 0110000 0101011 0110000 0110001 0101011 0110111}[/itex]
[itex]\texttt{0111010 0101101 0101010 0111000 0110010 0111110 0110001}[/itex]
translate back to ASCII:
[itex]\texttt{10+ 01 +7: -*8 2>1}[/itex]
where, for clarity, I’ve ignored the punctuation and not encrypted the spaces. In contrast to the case above, each unique letter is shifted by a different amount. This makes things more complicated, but the primary weakness of the standard shift cipher remains: the statistics of the plaintext are preserved. I do have to work a little harder, though, because the key can’t be recovered by decrypting only a few characters. Since each unique letter is shifted by a different amount, there are as many keys as there are letters in the alphabet—in this case, [itex]2^7 = 128[/itex] for the 7-bit ASCII alphabet that we’re using. But it’s the same game—use character frequencies to recover the plaintext letters, and once you’ve gotten the first few, the rest can probably be gotten from context.
Affine cipher
Instead of adding the key to the plaintext letters, there is a family of ciphers with a substitution rule based on multiplication by the key. These are known as affine ciphers and invoke the transformation
\begin{equation}
\label{affine}
c = (dp + m)\,{\rm mod}\,N,
\end{equation}
where [itex]d[/itex] and [itex]m[/itex] are integers. The shift cipher is an affine cipher with [itex]d=1[/itex]. To focus on the effect of the multiplication, let’s take [itex]m=0[/itex] and see what happens for [itex]d=4[/itex]. If we label the letters of the English alphabet by the numbers 0-25, we get the following mapping shown in Table 1:
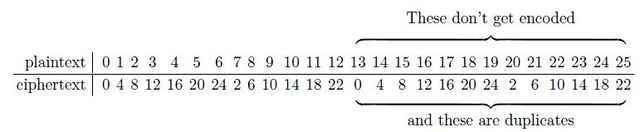
Table 1. Affine cipher with [itex]d=4[/itex] and [itex]m=0[/itex]. The ciphertext repeats after only 13 characters, and so not all plaintext characters are uniquely encoded. Notice how the ciphertext alphabet takes hops through the plaintext alphabet [itex]d=4[/itex] times, repeating halfway through.
Half-way through the plaintext alphabet the ciphertext repeats! As a result, half of the plaintext letters (those beyond M, letter 12) have no unique ciphertext equivalent and so effectively cannot be coded. We have an incomplete and, because of the duplicates, a non-invertible cipher. How did this happen? Let’s look a bit more closely at the congruence Eq. (\ref{affine}) for the case of [itex]m=0[/itex]. The congruence [itex]c=dp\,{\rm mod}\,N[/itex] can be written
\begin{equation}
\label{defk}
c = dp – kN,
\end{equation}
where [itex]k[/itex] counts the number of times we wind around the [itex]{\rm mod}\,N[/itex] “clock” (it takes on non-negative integer values.) So, for example, when [itex]dp > N[/itex], we take [itex]k=1[/itex]; when [itex]dp > 2N[/itex], we take [itex]k=2[/itex], and so on. This expression is the equivalent of taking the remainder of [itex]dp[/itex] upon division by [itex]N[/itex]. If [itex]d[/itex] and [itex]N[/itex] have a greatest common divisor, [itex]x>1[/itex] (written [itex]x={\rm gcd}(d,N)>1[/itex]), then we can write [itex]d = fx[/itex] and [itex]N=gx[/itex] for integers [itex]f < d[/itex] and [itex]g< N[/itex]. Then the congruence above becomes
\begin{equation}
c = x(fp – kg) = x(fp\,{\rm mod}\,g).
\end{equation}
This reveals that regardless of the value of [itex]p[/itex], the corresponding ciphertext, [itex]c[/itex], will always be a multiple of [itex]x[/itex]. Since our ciphertext alphabet is equivalent to the set of numbers [itex][0,25][/itex]—not all of which are multiples of the same integer [itex]x[/itex]—it is evident that the affine cipher with [itex]d=4[/itex] and [itex]m=0[/itex] cannot generate a complete ciphertext alphabet. In the specific case of [itex]d=4[/itex] and [itex]m=0[/itex], [itex]x=2[/itex] with the result that all the ciphertext characters are even. Since there are more plaintext than ciphertext characters, the cipher is also not unique4 and so cannot be inverted. Only when [itex]{\rm gcd}(d,N)=1[/itex]—when [itex]d[/itex] and [itex]N[/itex] are relatively prime—is the affine cipher complete and invertible5.
This means that the use of the affine cipher is constrained by the existence of pairs [itex](d,N)[/itex] that are relatively prime. There are only 12 numbers for which [itex]{\rm gcd}(26,d) = 1[/itex], and with 26 possibilities for [itex]m[/itex], there are [itex]26\times 12 = 312[/itex] different affine cipher prescriptions. Even if the affine cipher was difficult to break via frequency analysis, with only 312 versions it is almost more economical to recover the plaintext through brute force. But it turns out that the general affine cipher is just as susceptible to frequency analysis as the shift cipher. This family of ciphers preserves frequency statistics because each unique plaintext character is replaced by a unique ciphertext character—it is said that the ciphertext is drawn from a single alphabet. Even when the ciphertext alphabet appears random (as in the example of the shift cipher [itex]{\rm mod}\,2[/itex])—even if the alphabet is random—there is still a one-to-one mapping between the [itex]p[/itex]’s and the [itex]c[/itex]’s and careful analysis that leverages the grammar and syntax of the plaintext language will break the cipher. These techniques are wide-ranging and might include character frequencies, the expected locations of vowels in short ciphertext words, common word-beginning letters (like [itex]\texttt{T}[/itex] and [itex]\texttt{A}[/itex]) and word-ending letters (like [itex]\texttt{E}[/itex] and [itex]\texttt{S}[/itex]), words with tell-tale patterns (like [itex]\texttt{COMMITTEE}[/itex]), even perhaps a frequency analysis of two- or three-letter groupings (so-called digrams and trigrams: [itex]\texttt{TH}[/itex] and [itex]\texttt{AND}[/itex] are quite common) [2]. Ciphers that employ a single ciphertext alphabet are known as monoalphabetic, so to get our bearings, the affine and shift ciphers are examples of monoalphabetic, monographic ciphers. They are instructive, but as some of the earliest known encryption schemes, they are simple and weak. As I said at the beginning—studying broken ciphers yields insights into strong cipher design. What’s the lesson from studying affine ciphers? We need more alphabets.
From Vigenére to Vernam: the quest for more alphabets
Adding more alphabets is easy. Consider the shift cipher: instead of using a single key, [itex]m[/itex], to encrypt the entire plaintext, why not employ several? This is the idea behind the Vigenére cipher6—there is a different key, [itex]m_i[/itex], depending on the position in the plaintext. For example, suppose we have three keys: [itex]m_1 = 2[/itex], [itex]m_2 = 7[/itex], and [itex]m_3=4[/itex], where the subscript denotes the position, [itex]{\rm mod}\,i[/itex], of the plaintext character to be encrypted, i.e. we shift the first letter by 2, the next by 7, the next by 4, and the next by 2, and so on. All of the [itex]m_i[/itex] can be enumerated in a table called the cipher tabula recta (imaginatively, ruled table):

Fig 2. First nine lines of the Vigenére tabula recta: plaintext alphabet, [itex]p[/itex], across the top with corresponding ciphertext alphabets, [itex]m[/itex], indexed by shift number. The table was useful for encryption and decryption back in the olden days; now it’s mostly helpful for visualizing the different alphabets.
To create a Vigenére key we simply select a sequence of the [itex]m_i[/itex], say, [itex]k=m_1m_2m_3 = 274[/itex] as above. Or, better yet, we select a secret keyword, like [itex]\texttt{MARMOT}[/itex]. Encryption proceeds as follows:
[itex]\texttt{THE DUDE IS NOT INX}[/itex]
+
[itex]\texttt{MAR MOTM AR MOT MAR}[/itex]
—————–
[itex]\texttt{GIWQJ XRJKA DNVNP}[/itex]
We apply the key, [itex]\texttt{MARMOT}[/itex], in six-letter chunks across the whole plaintext7. Also, notice that we’ve padded the plaintext with [itex]\texttt{X}[/itex]’s (here only one) so that the ciphertext can be made into groups of five. The salient feature of this cipher is that like-plaintext characters do not generally encrypt to like-ciphertext. In our example, the first and third [itex]\texttt{D}[/itex]’s in [itex]\texttt{DUDE}[/itex] encrypt to [itex]\texttt{M}[/itex] and [itex]\texttt{T}[/itex], respectively. Furthermore, the second [itex]\texttt{E}[/itex] also encrypts to [itex]\texttt{M}[/itex]. The cipher is not one-to-one—it’s both many-to-one and one-to-many. In general, for a key with [itex]n[/itex] unique characters, each individual plaintext character could represent any of [itex]n[/itex] different ciphertext characters, depending on its position—the cipher is said to use [itex]n[/itex] alphabets. What this means is that the frequencies of the plaintext letters—like [itex]\texttt{D}[/itex] above—are distributed among several distinct ciphertext letters. By employing multiple alphabets, the Vigenére cipher achieves what the monoalphabetic ciphers failed to: it nicely hides the patterns of language and character frequencies of the plaintext by spreading them out among the ciphertext8. It offers up a fair helping of confusion to our fellow cryptanalysts. What can he do about it?
For one, he can study the frequency distribution of the ciphertext to determine whether the cipher is a simple shift or Vigenére, and if it’s the latter, how many alphabets were used. This involves bringing some statistical muscle to bear on a quantity called the measure of roughness that characterizes the choppiness of the frequency distribution [2],
\begin{equation}
\label{rho}
\rho = \sum_{i}^N \left(P_i – \frac{1}{N}\right)^2.
\end{equation}
This measure gives the average squared deviation9 of the observed character frequencies from a uniform distribution. [itex]P_i[/itex] is the probability that the [itex]i^{th}[/itex] character of the [itex]N[/itex]-character alphabet appears in the message: if all characters are equiprobable, [itex]\rho[/itex] is exactly zero. Notice that [itex]\rho[/itex] has the form of the chi-square statistic, [itex]\rho = Nn\chi^2n[/itex], where [itex]n[/itex] is the total number of characters in the message. This gives it some statistical street cred: the p-value10 associated with a given value of [itex]\rho[/itex] can be computed to determine how significantly, in a statistical sense, the ciphertext deviates from a uniform distribution. Because monoalphabetic ciphers retain the frequency characteristics of the plaintext, they have more roughness on average than polyalphabetic ciphers; the measure of roughness continues to decrease as alphabets are added (the distribution approaches uniformity on average when the number of alphabets is equal to the number of characters, [itex]N[/itex], in the alphabet.) In Figure 3 a frequency analysis of letters from the first chapter of the novel Great Expectations is presented, along with the frequency distributions of a couple of different ciphertexts:
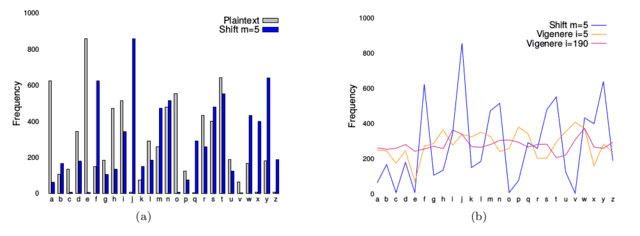 Fig 3. (a) Frequency distributions of letters from the 1st chapter of the novel Great Expectations by Charles Dickens: plaintext (gray) and ciphertext (blue) generated from a simple shift cipher with [itex]m=5[/itex]. The distributions have identical statistics. (b) Frequency distributions of a few different ciphertexts: the same shift cipher from (a) (using a line graph instead of bars for clarity), a Vigenére cipher with a 5-character key (orange), and a 190-character key (purple).
Fig 3. (a) Frequency distributions of letters from the 1st chapter of the novel Great Expectations by Charles Dickens: plaintext (gray) and ciphertext (blue) generated from a simple shift cipher with [itex]m=5[/itex]. The distributions have identical statistics. (b) Frequency distributions of a few different ciphertexts: the same shift cipher from (a) (using a line graph instead of bars for clarity), a Vigenére cipher with a 5-character key (orange), and a 190-character key (purple).
As we’ve discussed, the shift cipher does not affect the shape of the distribution, while the Vigenére cipher smooths out the choppiness.
If the key has a length of [itex]i[/itex], then every [itex]i^{th}[/itex] plaintext character is shifted by the same key character, e.g. characters [itex]\{p_1, p_{1+i}, p_{1+2i}, \cdots\} = \{p_{1\, {\rm mod}\, i}\}[/itex] are shifted by the same amount, characters [itex]\{p_2, p_{2+i}, p_{2+2i}, \cdots\} = \{p_{2\, {\rm mod}\, i}\}[/itex] are shifted by the same amount, and so on up to [itex]\{p_{(i-1)\, {\rm mod}\, i}\}[/itex]. The full plaintext is effectively broken up into [itex]i[/itex] smaller plaintext pieces, [itex]\{p_{j\, {\rm mod}\, i}\}[/itex] for [itex]0 \leq j < i[/itex], each separately encrypted by a different shift cipher. The corresponding ciphertexts, [itex]\{c_{j\, {\rm mod}\, i}\}[/itex], since they result from the [itex]\{p_{j\, {\rm mod}\, i}\}[/itex] by simple shifts, share frequency statistics with the [itex]\{p_{j\, {\rm mod}\, i}\}[/itex].
We can use this fact to discover the length of the key. Suppose the cipher is Vigenére with a 5-character key. First, we examine the frequency distribution of characters in the full ciphertext; if the cipher is anything other than a monoalphabetic substitution, this won’t yield anything promising. Next, we test for a two-character Vigenére key by computing the measures of roughness of two groups of ciphertext, [itex]\{c_{0\, {\rm mod}\, 2}\}[/itex] and [itex]\{c_{1\, {\rm mod}\, 2}\}[/itex], then we do this for three groups, [itex]\{c_{0\, {\rm mod}\, 3}\}[/itex], [itex]\{c_{1\, {\rm mod}\, 3}\}[/itex], and [itex]\{c_{2\, {\rm mod}\, 3}\}[/itex], and so on. This process is illustrated in Figure 4:
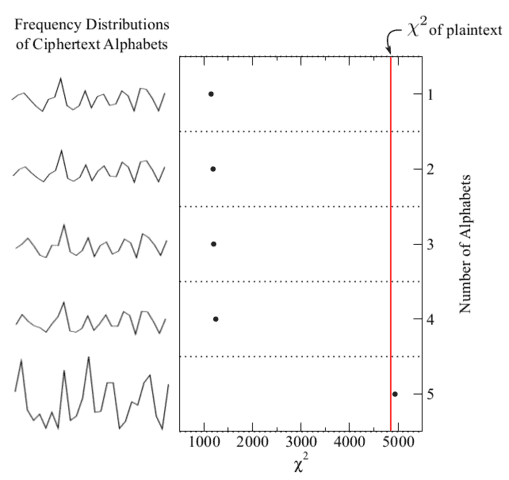
Fig 4. [itex]\chi^2[/itex] values of ciphertext character frequency distributions when the ciphertext is divided into 1, 2, 3, 4, and 5 monoalphabets. For multiple monoalphabets, there are multiple distributions; only one is shown. For multiple monoalphabets the average [itex]\chi^2[/itex] is computed.
Notice that the frequency of ciphertext characters is roughly uniform until we try five alphabets—the length of th key—at which point the [itex]\chi^2[/itex] of the frequency distribution increases dramatically to match that of the plaintext11. Once the length of the key has been determined in this way, the problem has been effectively broken up into a more manageable collection of simple shift ciphers.
As the length of the key increases, this method of analysis gets progressively less reliable. For a key of length [itex]i[/itex] and a plaintext message of length [itex]n[/itex], there are [itex]n/i[/itex] characters in each of the [itex]i[/itex] plaintext and ciphertext pieces, [itex]\{p_{j\, {\rm mod}\, i}\}[/itex] and [itex]\{c_{j\, {\rm mod}\, i}\}[/itex]. If the number of characters in each ciphertext piece is too small, the frequency distributions of the [itex]\{c_{j\, {\rm mod}\, i}\}[/itex] will not resemble a representative sample of the plaintext language and our ability to detect deviations from uniformity will be challenged. Indeed, as [itex]i \rightarrow n[/itex], we lose all ability as the plaintext pieces [itex]\{p_{j\, {\rm mod}\, i}\}[/itex] reduce to individual characters. This result argues for a key with the same length as the message with as little repetition as possible (so that different instances of the same plaintext character encrypt to any ciphertext character with equal preference). Repetition is minimized in practice by drawing each character in the key randomly from the alphabet, a system known as the Vernam cipher. When the key is random, so too is the ciphertext. The result is the most formidable of ciphertexts—a cryptanalytic nightmare that is unbreakable even in principle if implemented properly.
In 1949, Claude Shannon proved [1] that if the key is random, as long as the message, and never reused, then the Vernam cipher is theoretically secure, i.e. it cannot be broken even in principle. This system is known as a one-time pad, named for the practice of writing the random key on notepads secretly shared between sender and receiver12. As keys were used, pages were torn out of the pad to ensure one-time use. Because the cipher employs as many alphabets as characters of plaintext, the key can be anything—a given ciphertext, therefore, retains none of the characteristics of the message and might decrypt to any possible plaintext. Intercepting the ciphertext is of no help to the cryptanalyst since all plaintexts are equally likely: this condition is called perfect secrecy. One-time-pads were popular among Soviet spies during World War II, though they weren’t always diligent with the “one-time” part of the concept, enabling U.S. and British intelligence services to break portions of Soviet encrypted communications13. Key reuse was undoubtedly due to the logistical difficulty of deploying and securing long, random keys. But what if we’re willing to skimp a bit on the whole randomness thing?
One way to employ a key as long as the message is to somehow use the message itself as the key. The autokey is a substitution cipher that uses the message plaintext, shifted by a certain amount relative to the message, as the key. A shared keyword prepended to the message imparts the shift and enables decryption. For example,
[itex]\texttt{Weholdthesetruthstobeselfevidentthatallmenarecreatedequal…}[/itex]
[itex]\texttt{+}[/itex]
[itex]\texttt{JEFFERSONWeholdthesetruthstobeselfevidentthatallmenarecre…}[/itex]
——————————————————————————–
[itex]\texttt{gjnuqvmwspjbggxbayhgykzfnxpxfjgyfnfpjpqayhisyddqnysewvxsq…}[/itex]
The autokey is Vigenére cipher with a message-length key in which plaintext character [itex]p_i[/itex] is shifted by [itex]p_{i+k}[/itex], for a [itex]k[/itex]-letter keyword. Because the shifts are imparted by the plaintext itself, they are not random; rather, for long messages, their statistics conform to those of the English language (i.e. shifts by 5, corresponding to the letter [itex]\texttt{e}[/itex], will occur most often on average, followed by shifts of 1, corresponding to the letter [itex]\texttt{a}[/itex], and so on). But is it obvious that shifting non-random plaintext characters by amounts drawn from a non-random key won’t result in a random ciphertext? Is shifting by, say, five characters more likely to result in a uniform ciphertext than shifting by ten? In general, how do the statistics of the ciphertext depend on the amount of shift between plaintext and key?
Since the keyword is typically short, it does not contribute significantly to the ciphertext statistics so to isolate the effect of the shift amount, we’ll do away with the keyword and just wrap the plaintext key back on itself. First, consider a shift of zero: ignoring the fact that decryption would be impossible, we do very little to obscure the plaintext statistics. Because each character is added to itself, each ciphertext character, [itex]c_j[/itex], inherits the frequency statistics of the two plaintext characters [itex]p_i[/itex] and [itex]p_l[/itex] for which: [itex]j = 2i = 2l \mod 26[/itex]. For example, [itex]\texttt{a}[/itex] and [itex]\texttt{s}[/itex] both encrypt to [itex]\texttt{b}[/itex]. The result is that high-frequency plaintext characters transform to high-frequency ciphertext, and the lack of any ciphertext characters [itex]c_i[/itex] for odd [itex]i[/itex] is notable and further inhibits mixing. Alas, as Figure 5 (a) shows, the [itex]\chi^2[/itex] value of the ciphertext for a shift of [itex]n=0[/itex] is near astronomical, [itex]\chi^2 \approx 10,000[/itex].
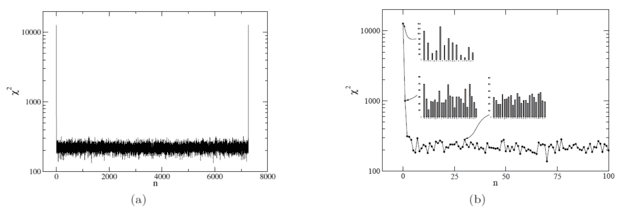
Fig 5. (a) [itex]\chi^2[/itex] values of ciphertexts generated by shifting the plaintext by amounts [itex]n=0,1,2,\dots[/itex]. (b) Zoom in on the region [itex]n\in [0,100][/itex] with ciphertext character frequencies shown for [itex]n=0,1[/itex] and [itex]30[/itex].
A shift of [itex]n=1[/itex] is a sharp improvement, but the statistics are still far from uniform. This is interesting, since now we have much more mixing: each ciphertext character, [itex]c_j[/itex], can arise from any two plaintext characters [itex]p_i[/itex] and [itex]p_l[/itex] with [itex]j = i + l\mod 26[/itex]. So what’s going on here? Since each character of ciphertext results from combining consecutive characters of plaintext, we only expect the ciphertext to be uniform if each letter pair, [itex]p_i p_l[/itex], is equiprobable. But in English, we know this isn’t the case: the letters [itex]\texttt{th}[/itex] appear way more often than the letters [itex]\texttt{cz}[/itex]; the combination [itex]\texttt{er}[/itex] is more frequent than the pair [itex]\texttt{dl}[/itex]. The ciphertext character distribution resulting from a shift of [itex]n=1[/itex] therefore embodies the digraph statistics of English at large.
Interestingly, once we try [itex]n=2[/itex] the [itex]\chi^2[/itex] value more or less settles down. Evidently, in English, no pair of characters is more likely to be found separated by a single letter than as found separated by two, three, or any number of letters. Notice, though, that the distribution settles down to around [itex]\chi^2 \approx 250[/itex] for [itex]n \in [2,L-2][/itex] (where [itex]L[/itex] is the length of the message), quite far from a uniform distribution (see Figure 6: strings generated by a typical pseudo-random number generator have [itex]\chi^2 \approx 30[/itex]; not truly random, but much more uniform than the autokey.) This means that there must be some preference for some character pairs over others; I suspect though I’ve not verified that any preference is due to single character frequencies, i.e. that [itex]\texttt{e}[/itex]’s are more likely to pair with other [itex]\texttt{e}[/itex]’s sole because it is the most common character. In comparison with Figure 6, the autokey for [itex]n \in [2,L-2][/itex] leads to a ciphertext with frequency distribution similar to a Vigenére cipher with a 30-character pseudo-random key.
References and Footnotes
[1] Shannon, C. E., Communication Theory of Secrecy Systems. Bell System Technical Journal, 28 (1949).
[2] Sinkov, A., Elementary Cryptanalysis: A Mathematical Approach. Mathematical Association of America
Textbooks, (1966).
1A good encryption scheme generates a ciphertext that is highly randomized: if only a single bit of plaintext is changed, the ciphertext should change in a significant and unpredictable way (by, for example, flipping half of the output bits.) back
2ASCII is the American Standard Code for Information Interchange. It is a character-encoding scheme that converts 7-bit binary numbers into the many different printable characters used in written communication. back
3XOR is short for exclusive OR, a logical operation that returns 0 unless the operands are different and 1 otherwise, i.e. [itex]1+1=0[/itex], [itex]0+0=0[/itex], [itex]1+0 = 0+1 = 1[/itex]. back
4For a general congruence, [itex]a=b\,{\rm mod}\,n[/itex], [itex]a[/itex] begins to repeat only when [itex]b\geq n[/itex]. Here, though, multiplication by [itex]d=4[/itex] has resulted in (at least) two distinct plaintext characters: [itex]p_1[/itex] and [itex]p_2[/itex] both [itex]< 26[/itex], that map to the same ciphertext character, i.e.,
\begin{eqnarray}
c &=& 4p_1 {\rm mod}\,26 = 4p_2 {\rm mod}\,26 \\
\label{eqk}
&=& 4p_1 -26k_1 = 4p_2 -26k_2.
\end{eqnarray}
If we solve for [itex]p_1[/itex] in terms of [itex]p_2[/itex], we get
\begin{eqnarray}
p_1 &=& p_2 + \frac{26}{4}(k_1-k_2) \\
\label{pmod}
&=& p_2\,{\rm mod}\,\frac{26}{4}(k_2-k_1),
\end{eqnarray}
as the condition that both [itex]p_1[/itex] and [itex]p_2[/itex] give the same [itex]c[/itex]. If [itex]p_1 = p_2\,{\rm mod}\,26[/itex], then [itex]p_1[/itex] and [itex]p_2[/itex] only give the same [itex]c[/itex] if [itex]p_1=p_2[/itex]. If this were the case, then we’d get a well-behaved cipher and there would be no repeats. Now, from Eq. (\ref{pmod}), we see that there is a dependence on [itex]k_2-k_1[/itex]. If we take [itex]k_1 =0[/itex], then from Eq. (\ref{eqk}) and the discussion following Eq. (\ref{defk}), we have [itex]4p_1 < 26[/itex], so that [itex]p_1[/itex] is from the 1st quarter of the alphabet. If we then take [itex]k_2=1[/itex], we’ve got [itex]p_2[/itex] coming from the 2nd quarter of the alphabet. So the relation Eq. (\ref{pmod}) with [itex]k_2-k_1 = 1-0=1[/itex] tells us whether a [itex]p[/itex] from the 1st quarter of the alphabet gives the same [itex]c[/itex] as a [itex]p[/itex] from the 2nd quarter. In this case Eq (\ref{pmod}) becomes [itex]p_1 = p_2 + 26/4[/itex]. Because both [itex]p_1[/itex] and [itex]p_2[/itex] must be integers, this equation has no solutions and so no two such [itex]p[/itex]’s exist. What about finding a match between a [itex]p[/itex] in the 1st and a [itex]p[/itex] in the 3rd quarter? For [itex]k_2-k_1 = 2[/itex] we get [itex]p_1 = p_2\, {\rm mod}\,13[/itex]! This means that after making it only half-way through the plaintext alphabet, we stumble upon a character, [itex]p_2[/itex], that gives the same [itex]c[/itex] as [itex]p_1[/itex]. This is just what we see in Table 1. back
5What we’re actually discovering here about the congruence Eq. (\ref{defk}) when [itex]{\rm gcd}(d,N)>1[/itex] is that it is not onto or one-to-one. A function, [itex]f[/itex], is onto if, for every value in the range, [itex]y_i[/itex], there exists an [itex]x_i[/itex] in the domain such that [itex]y_i = f(x_i)[/itex]. A function is one-to-one if [itex]f(x_i)=f(x_j)[/itex] only if [itex]x_i = x_j[/itex]. Eq. (\ref{defk}) with [itex]d=4[/itex], [itex]m=0[/itex], and [itex]N=26[/itex] is not onto because there are ciphertext characters that do not encode any plaintext characters (all the odd [itex]c_i[/itex]); it is not one-to-one because each [itex]c_i[/itex] encodes two plaintext characters, [itex]p_i \neq p_j[/itex]. When the domain and range of a function are equivalent discrete sets (in this case [itex]c=p=[0,25][/itex]), [itex]f[/itex] is onto if and only if it is one-to-one. back
6The cipher is named for Blaise de Vigenére, a 16th century French diplomat who had nothing to do with it. back
7Because the Vigenére cipher operates on characters in key-length blocks, it is sometimes described as a block cipher, or as a polygraphic cipher. Neither of these designations is correct. The Vigenére cipher still operates on single characters, with a position-dependent single character subkey (the [itex]m_i[/itex]). Polygraphic or block substitution ciphers use multiple-character strings as the basis of their of substitutions, so for example, in the case of a six-character cipher, the word [itex]\texttt{RANSOM}[/itex] would always map to the same ciphertext string. This is generally not true of the Vigenére cipher. back
8By “spread out” I mean that a frequency analysis of ciphertext characters reveals few features—that most characters appear with similar frequency (in the limit that the number of alphabets approaches 26, on average all ciphertext characters appear with equal frequency). I do not mean to imply that the Vigenére cipher mixes the statistics of the plaintext throughout the ciphertext, in the spirit of Shannon’s diffusion criterion. Small, localized changes to plaintext still result in small, localized changes to the ciphertext. back
9An average squared deviation is necessary because the average deviation is zero. back
10The p-value is the integral over the chi-square distribution function [itex]\int_{\chi^2}^\infty P_\nu (y)\,dy[/itex] of [itex]\nu = N-1[/itex] degrees of freedom. The p-value gives the probability that the observed deviations from uniformity arise from chance alone. back
11These are huge values of [itex]\chi^2[/itex] per the 25 degrees of freedom, meaning that even the “uniform” ciphertexts are strongly statistically distinct from true uniform distributions. This is expected for such a short key, in which case we cannot use p-values to “detect” the key length, but must rely on the relative change in [itex]\chi^2[/itex] (or [itex]\rho[/itex]). As the size of a random key increases, we expect the ciphertext to become more uniform. This is reflected in a decreasing chi-squared per degrees of freedom. For the first chapter of Great Expectations examined in this article, the Vigenére cipher becomes more and more uniform with increasing key size until the key reaches a length of around 1000 characters, after which the degree of uniformity remains approximately constant:
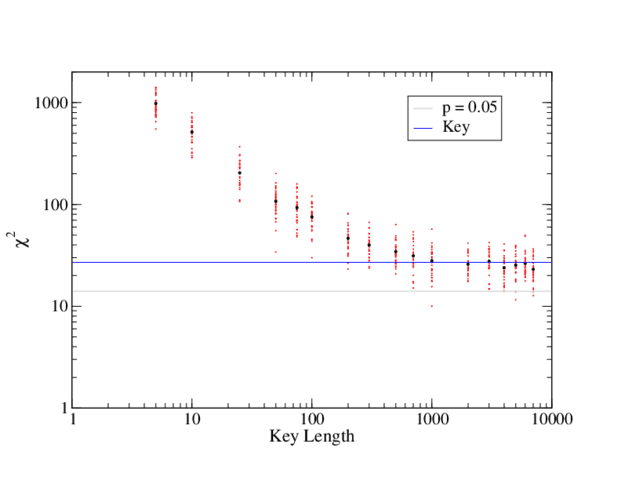
Fig 6. [itex]\chi^2[/itex] values of Vigenére ciphertexts encrypted with keys of increasing length. For each key length, the first chapter of Great Expectations was encrypted with 30 randomly generated keys (red points); the average [itex]\chi^2[/itex] for each key length is also shown (black points). The gray line marks the [itex]\chi^2[/itex] marking the 0.05 significance level. The blue line is the average [itex]\chi^2[/itex] calculated from the sample of random 1000-character keys.
The ciphertext is still not statistically uniform: the average [itex]\chi^2[/itex] of ciphertexts with key lengths [itex]\geq[/itex] 1000 is around 26, whereas [itex]\chi^2 \leq 14[/itex] for a [itex]0.05[/itex] significance level (gray line in Figure 6). Is this lack of significant uniformity a feature of the type of cipher or the key? The average [itex]\chi^2[/itex] of a sample of 1000-character-keys (blue line in Figure 6) agrees well with the average [itex]\chi^2[/itex] of the ciphertexts encrypted with these keys. The Vigenére cipher, therefore, appears to achieve the same degree of uniformity as the key when the key length reaches 1000 characters or around a length of [itex]40N[/itex] for an [itex]N[/itex]-character alphabet. Presumably, a more uniform key would increase the uniformity of the Vigenére ciphertext. back
12For long messages, one-time pads are difficult to implement because the key exchange is impractical; instead, keys must be pre-deployed among a fixed set of parties and kept secure for long periods of time. Modern implementations of Vernam ciphers include stream ciphers that generate a pseudo-random keystream and employ bit-wise encryption. These, however, still employ a fixed-sized key that seeds the pseudo-random number generator and so are not true one-time pads. back
13This decades-long cryptanalysis effort was part of the famous U.S/U.K. VENONA project targeting the encrypted communications of Soviet intelligence agencies. Over 3000 messages were at least partially decrypted revealing important information, including Soviet espionage targeting the Manhattan Project.back
After a brief stint as a cosmologist, I wound up at the interface of data science and cybersecurity, thinking about ways of applying machine learning and big data analytics to detect cyber attacks. I still enjoy thinking and learning about the universe, and Physics Forums has been a great way to stay engaged. I like to read and write about science, computers, and sometimes, against my better judgment, philosophy. I like beer, cats, books, and one spectacular woman who puts up with my tomfoolery.

Chosen-plain/ciphertext attacks and hardware side channels are the bacon and eggs of [URL=’https://en.wikipedia.org/wiki/Cryptanalysis’]Cryptanalysis[/URL].
[quote]
In addition to mathematical analysis of cryptographic algorithms, cryptanalysis includes the study of [URL=’https://en.wikipedia.org/wiki/Side-channel_attacks’]side-channel attacks[/URL] that do not target weaknesses in the cryptographic algorithms themselves, but instead exploit weaknesses in their implementation.[/quote]
[MEDIA=youtube]DU-HruI7Q30[/MEDIA]
“if an attacker can control parts of the plaintext”
I just remembered the canonical example of that, Heil Hitler.
“I didn’t have compression in mind. ”
But your scheme is a form of compression, since the encoded text gets shorter.
Anyway, just wanted to point out that getting encryption right is hard, so many things one have to consider.
And yes, the various side channels and so on they manage to exploit is impressive and does indeed feel like Spy vs Spy :)
“n the other hand, if an attacker can control parts of the plaintext, compression can leak information as explained here: [URL]http://security.stackexchange.com/a/19914[/URL]”
I didn’t have compression in mind. Nevertheless, the tactic you mention is clever. I’m reminded of the old “Spy Versus Spy” cartoons from Mad Magazine.:wink:
“It might be worthwhile to mention that good encryption practice would be to keep the message as short as possible to make statistical analysis more difficult. In the extreme, shortened plaintext morphs into code and encryption becomes unnecessary.”
On the other hand, if an attacker can control parts of the plaintext, compression can leak information as explained here: [URL]http://security.stackexchange.com/a/19914[/URL]
Well done, I learned a lot. Thank you for the education.
It might be worthwhile to mention that good encryption practice would be to keep the message as short as possible to make statistical analysis more difficult. In the extreme, shortened plaintext morphs into code and encryption becomes unnecessary.
Superb Insight!