Tensors Explained: Scalars, Vectors, Matrices & Math
Table of Contents
Introduction
Let me start with a counter-question. What is a number? Before you laugh, there is more to this question than one might think. A number can be something we use to count or more advanced an element of a field like real numbers. Students might answer that a number is a scalar. This is the appropriate answer when vector spaces are around. But what is a scalar? A scalar can be viewed as the coordinate of a one-dimensional vector space, the component of a basis vector. It means we stretch or compress a vector. But this manipulation is a transformation, a homomorphism, a linear mapping. So the number represents a linear mapping of a one-dimensional vector space. It also transports other numbers to new ones. Thus it is an element of ##\mathbb{R}^*##, the dual space: ##c \mapsto (a \mapsto \langle c,a \rangle)##. Wait! Linear mapping? Aren’t those represented by matrices? Yes, it is a ##1 \times 1## matrix and even a vector itself.
So without any trouble, we have already found that a number is
Different Perspectives on Numbers
- An element of a field, e.g. ##\mathbb{R}##.
- A scalar.
- A coordinate.
- A component.
- A transformation of other numbers, an element of a dual vector space, e.g. ##\mathbb{R}^*##
- A matrix.
- A vector.
Numbers, Vectors and Matrices
As you might have noticed, we can easily generalize these properties to higher dimensions, i.e. arrays of numbers, which we usually call vectors and matrices. I could as well have asked: What is a vector, what is a matrix? We would have found even more answers, as matrices can be used to solve systems of linear equations, some form matrix groups, others play an important role in calculus as Jacobi matrices, and again others are number schemes in stochastic. In the end, they are only two-dimensional arrays of numbers in a rectangular shape. A number is even the one-dimensional special case of the two-dimensional array matrix.
What Is a Tensor?
This sums up the difficulties when we ask: What is a tensor? Depending on whom you ask, how much room and time there is for an answer, where the emphases lie, or what you want to use them for, the answers may vary significantly. In the end, they are only multi-dimensional arrays of numbers in a rectangular shape.1) 2).
$$ \begin{aligned} \begin{bmatrix}2\end{bmatrix} &\qquad \begin{bmatrix}1\\1\end{bmatrix} &\qquad \begin{bmatrix}0 & -1\\ 1 & 0\end{bmatrix} \\[6pt] \text{scalar} &\qquad \text{vector} &\qquad \text{matrix} \\[6pt] – &\qquad (1,0)\ \text{tensor} &\qquad (2,0)\ \text{tensor} \end{aligned} $$
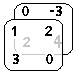
##(3,0)\; tensor##
Intuition and Importance
Many students are used to dealing with scalars (numbers, mass), vectors (arrows, force), and matrices (linear equations, Jacobi-matrix, linear transformations, covariances). The concept of tensors, however, is often new to them at the beginning of their study of physics. Unfortunately, they are as important in physics as scalars, vectors, and matrices are. The good news is, they aren’t any more difficult than the former. They only have more coordinates. This might seem to go to the expense of clarity, but there are methods to deal with it. E.g. a vector also has more coordinates than a scalar. The only difference is, that we can sketch an arrow, whereas sketching an object defined by a cube of numbers is impossible. And as we can do more with matrices, than we can do with scalars, we can do even more with tensors, because a cube of numbers, or even higher dimensional arrays of numbers, can represent a lot more than simple scalars and matrices can. Furthermore, scalars, vectors, and matrices are also tensors. This is already the entire secret about tensors. Everything beyond this point is methods, examples and language, in order to prepare for how tensors can be used to investigate certain objects.
Tensor Definitions
Coordinate and Abstract Views
As variable as the concept of tensors is as variable are possible definitions. In coordinates, a tensor is a multi-dimensional, rectangular scheme of numbers: a single number as a scalar, an array as a vector, a matrix as a linear function, a cube as a bilinear algorithm, and so on. All of them are tensors, as a scalar is a special case of a matrix, all these are special cases of a tensor. The most abstract formulation is: A tensor ##\otimes_\mathbb{F}## is a binary covariant functor that represents a solution for a co-universal mapping problem on the category of vector spaces over a field ##\mathbb{F}## [3]. It is a long way from a scheme of numbers to this categorical definition. To be of practical use, the truth lies – as so often – in between. Numbers don’t mean anything without basis, and categorial terms are useless in an everyday business where coordinates are dominant.
Tensor Product Properties
Definition: A tensor product of vector spaces ##U \otimes V## is a vector space structure on the Cartesian product ##U \times V## that satisfies
$$ \begin{aligned} (u+u’)\otimes v &= u \otimes v + u’ \otimes v\\ u \otimes (v + v’) &= u \otimes v + u \otimes v’\\ \lambda (u\otimes v) &= (\lambda u) \otimes v = u \otimes (\lambda v) \end{aligned} $$
This means a tensor product is a freely generated vector space of all pairs ##(u,v)## that satisfies some additional conditions such as linearity in each argument, i.e. bilinearity, which justifies the name product. Tensors form a vector space as matrices do. The tensor product, however, must not be confused with the direct sum ##U \oplus V## which is of dimension ##\operatorname{dim} U +\operatorname{dim} V## as a basis would be ##\{(u_i,0)\, , \,(0 , v_i)\}##, whereas in a tensor product ##U \otimes V##, all basis vectors ##(u_i,v_j)## are linearly independent and we get the dimension ##\operatorname{dim} U \cdot \operatorname{dim} V##. Tensors can be added and multiplied by scalars. A tensor product is not commutative even if both vector spaces are the same. Now obviously it can be iterated and the vector spaces could as well be dual spaces or algebras. In physics, tensors are often a mixture of several vector spaces and several dual spaces. It also makes sense to sort both kinds as the tensor product isn’t commutative.
Type (p,q) Tensors
Definition: A tensor ##T_q^p## of type ##(p,q)## of ##V## with ##p## contravariant and ##q## covariant components is an element (vector) of
$$ \mathcal{T}(V^p;V^{*}_q) = \underbrace{ V\otimes\ldots\otimes V}_{p\text{-times}}\otimes\underbrace{ V^*\otimes\ldots\otimes V^*}_{q\text{-times}} $$
By (1) this tensor is linear in all its components.
Tensor Examples
Rank and Shape
From a mathematical point of view, it doesn’t matter whether a vector space ##V## or its dual ##V^*## of linear functionals is considered. Both are vector spaces and a tensor product in this context is defined for vector spaces. So we can simply say
- A tensor of rank ##0## is a scalar: ##T^0 \in \mathbb{R}##.
- A tensor of rank ##1## is a vector: ##T^1 = \sum u_i##.
- A tensor of rank ##2## is a matrix: ##T^2 = \sum u_i \otimes v_i##.
- A tensor of rank ##3## is a cube: ##T^3 = \sum u_i \otimes v_i \otimes w_i##.
- A tensor of rank ##4## is a ##4##-cube and we run out of terms for them: ##T^4 = \sum u_i \otimes v_i \otimes w_i \otimes z_i##.
- ##\ldots## etc.
Dyadic Products and Matrices
If we build ##u \otimes v## in coordinates we get a matrix. Say ##u = (u_1,\ldots ,u_m)^\tau## and ##v = (v_1,\ldots , v_n)^\tau##. Then
$$ u \otimes v = u \cdot v^\tau = \begin{bmatrix} u_1v_1 & u_1v_2 & u_1v_3 & \ldots & u_1v_n\\ u_2v_1 & u_2v_2 & u_2v_3 & \ldots & u_2v_n\\ u_3v_1 & u_3v_2 & u_3v_3 & \ldots & u_3v_n\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ u_m v_1 & u_m v_2 & u_m v_3 & \ldots & u_m v_n \end{bmatrix} $$
Higher-order Tensors
Note that this is the usual matrix multiplication, row times column. But here the first factor is ##m## rows of length ##1## and the second factor is ##n## columns of length ##1##. It also means that this matrix is a matrix of rank one since it consists of different multiples of a single row vector ##v^\tau##. To write an arbitrary ##n \times n## matrix ##A## as a tensor, we need ##n## of those dyadic tensors, i.e.
$$ A = \sum_{i=1}^n u_i \otimes v_i $$
A generic “cube” ##u \otimes v \otimes w## will get us a “rank ##1## cube” as different multiples of a rank ##1## matrix stacked to a cube. An arbitrary “cube” would be a sum of these. And this procedure isn’t bounded by dimensions. We can go on and on. The only thing is, that already “cube” was a bit of a crutch to describe a three-dimensional array of numbers and we ran out of words other than tensor. A four-dimensional version (tensor) could be viewed as the tensor product of two matrices, which themselves are tensor products of two vectors and always sums of them.
Strassen Algorithm Example
Let us consider now arbitrary ##2 \times 2## matrices ##M## and order their entries such that we can consider them as vectors because ##\mathbb{M}(2,2)## is a vector space. Say ##(M_{11},M_{12},M_{21},M_{22})##. Then we get in
$$ \begin{aligned} M \cdot N &= \begin{bmatrix} M_{11} & M_{12} \\ M_{21} & M_{22} \end{bmatrix} \cdot \begin{bmatrix} N_{11} & N_{12} \\ N_{21} & N_{22} \end{bmatrix} \\[6pt] &= \begin{bmatrix} M_{11}N_{11}+M_{12}N_{21} & M_{11}N_{12}+M_{12}N_{22} \\ M_{21}N_{11}+M_{22}N_{21} & M_{21}N_{12}+M_{22}N_{22} \end{bmatrix} \\[6pt] &= \left(\sum_{\mu =1}^{7} u_{\mu }^* \otimes v_{\mu }^* \otimes W_{\mu}\right)(M,N) = \sum_{\mu =1}^{7} u_{\mu}^*(M) \cdot v_{\mu}^*(N) \cdot W_{\mu} \\[6pt] &= \bigg( \begin{bmatrix} 1\\0 \\0 \\1 \end{bmatrix}\otimes \begin{bmatrix} 1\\0 \\0 \\1 \end{bmatrix} \otimes \begin{bmatrix} 1\\0 \\0 \\1 \end{bmatrix} + \begin{bmatrix} 0\\0 \\1 \\1 \end{bmatrix}\otimes \begin{bmatrix} 1\\0 \\0 \\0 \end{bmatrix} \otimes \begin{bmatrix} 0\\0 \\1 \\-1 \end{bmatrix} \\ \qquad + \begin{bmatrix} 1\\0 \\0 \\0 \end{bmatrix}\otimes \begin{bmatrix} 0\\1 \\0 \\-1 \end{bmatrix} \otimes \begin{bmatrix} 0\\1 \\0 \\1 \end{bmatrix} + \begin{bmatrix} 0\\0 \\0 \\1 \end{bmatrix}\otimes \begin{bmatrix}-1\\0 \\1 \\0 \end{bmatrix} \otimes \begin{bmatrix} 1\\0 \\1 \\0 \end{bmatrix} \\ \qquad + \begin{bmatrix} 1\\1 \\0 \\0 \end{bmatrix}\otimes \begin{bmatrix} 0\\0 \\0 \\1 \end{bmatrix} \otimes \begin{bmatrix}-1\\1 \\0 \\0 \end{bmatrix} + \begin{bmatrix}-1\\0 \\1 \\0 \end{bmatrix}\otimes \begin{bmatrix} 1\\1 \\0 \\0 \end{bmatrix} \otimes \begin{bmatrix} 0\\0 \\0 \\1 \end{bmatrix} \\ \qquad + \begin{bmatrix} 0\\1 \\0 \\-1 \end{bmatrix}\otimes \begin{bmatrix} 0\\0 \\1 \\1 \end{bmatrix} \otimes \begin{bmatrix} 1\\0 \\0 \\0 \end{bmatrix} \bigg).(M,N) \end{aligned} $$
a matrix multiplication of ##2 \times 2## matrices which only needs seven generic multiplications ##u_{\mu}^*(M) \cdot v_{\mu}^*(N) ## to the expense of more additions. This (bilinear) algorithm is from Volker Strassen ##[1]##. It reduced the “matrix exponent” from ##3## to ##\log_2 7 = 2.807## which means matrix multiplication can be done with ##n^{2.807}## essential multiplications instead of the obvious ##n^3## by simply multiplying rows and columns. The current record holder is an algorithm from François Le Gall (2014) with an upper bound of ##O(n^{2.3728639}) [5]##. For the sake of completeness let me add, that these numbers are true for large ##n## and they start with different values of ##n##. For ##n=2## Strassen’s algorithm is already optimal. One cannot use less than seven multiplications to calculate the product of two ##2 \times 2## matrices. For larger matrices, however, there are algorithms with fewer multiplications. Whether these algorithms can be called efficient or useful is a different discussion. I once have been told that Strassen’s algorithm had been used in cockpit software, but I’m not sure if this is true.
Key Points from the Example
This example shall demonstrate the following points:
- The actual presentation of tensors depends on the choice of basis as well as it does for vectors and matrices.
- Strassen’s algorithm is an easy example of how tensors can be used as mappings to describe certain objects. The set of all those algorithms for this matrix multiplication forms an algebraic variety, i.e. a geometrical object.
- Tensors can be used for various applications, not necessarily only in mathematics and physics, but also in computer science.
- The obvious, here “Matrix multiplication of ##2 \times 2## matrices needs ##8## generic multiplications.” isn’t necessarily the truth. Strassen saved one.
- A tensor itself is a linear combination of let’s say generic tensors of the form ##v_1 \otimes \ldots \otimes v_m##. In the case of ##m=1## one doesn’t speak of tensors, but of vectors instead, although strictly speaking they would be called monads. In case ##m=2## these generic tensors are called dyads and in case ##m=3## triads.
- One cannot simplify the addition of generic tensors, it remains a formal sum. The only exception for multilinear objects is always $$ u_1 \otimes v \otimes w + u_2 \otimes v \otimes w = (u_1 +u_2) \otimes v \otimes w $$ where all but one factor are identical in which case we know it as distributive property.
- Matrix multiplication isn’t commutative. So we are not allowed the swap the ##u_\mu^*## and ##v_\mu^*## in the above example, i.e. a tensor product isn’t commutative either.
- Tensors according to a given basis are number schemes. Which meaning we attach to them depends on our purpose.
Applications in Physics and Algebra
However, these schemes of numbers called tensors can stand for a lot of things: transformations, algorithms, tensor algebras, or tensor fields. They can be used as a construction template for Graßmann algebras, Clifford algebras, or Lie algebras, because of their (co-)universal property. They occur at really many places in physics, e.g. stress-energy tensors, Cauchy stress tensors, metric tensors, or curvature tensors such as the Ricci tensor, just to name a few. Not bad for some numbers ordered in multidimensional cubes. This only reflects, what we’ve already experienced with matrices. As a single object, they are only some numbers in rectangular form. But we use them to solve linear equations as well as to describe the fundamental forces in our universe.
Sources
Sources
- Strassen, V., Gaussian elimination is not optimal, 1969, Numer. Math. (1969) 13: 354. doi:10.1007/BF02165411
- Werner Greub, Linear Algebra, Springer Verlag New York Inc., 1981, GTM 23
https://www.amazon.com/Linear-Algebra-Werner-Greub/dp/8184896336 - Götz Brunner, Homologische Algebra, Bibliografisches Institut AG Zürich, 1973
- Maximillian Ganster, Graz University of Technology, Lecture Notes Summer 2010, Vektoranalysis,
https://www.math.tugraz.at/~ganster/lv_vektoranalysis_ss_10/20_ko-_und_kontravariante_darstellung.pdf François Le Gall, 2014, Powers of Tensors and Fast Matrix Multiplication, https://arxiv.org/abs/1401.7714
Footnotes
##\underline{Footnotes:}##
1) Tensors don’t need to be of the same size in every dimension, i.e. don’t have to be built from vectors of the same dimension, so the examples below are already a special case even though the standard case in the sense that quadratic matrices appear more often than rectangular ones. ##\uparrow##
2) One might call a scalar a (0,0) tensor, but I will leave this up to the logicians. ##\uparrow##






Of course, because you defined ##(0,1)## as a tuple plus the absence of meaning and then reasoned that it has no meaning.It has no physical or geometric meaning, but can have mathematical meaning and properties. Those concepts are common in mathematics.
Of course, because you defined ##(0,1)## as a tuple plus the absence of meaning and then reasoned that it has no meaning. That's a tautology. ##(0,1)## has a meaning, as soon as it is associated with a point in a coordinate system, namely the vector from the origin to this point, even over ##mathbb{Z}_2##. It transforms, at the very least by permutation of the axis to ##(1,0)## and is of course a tensor, as all vectors are. Examples of matrices which aren't a representative of a linear transformation in some coordinate system, need to have a meaning attached to them, which excludes such a transformation. Maybe a matrix of pixels in an image. But even then each entry has a RGB coordinate and is again in some sense a tensor. Whether this tensor as a multilinear object makes any sense is another question.
Yes, but this is similar difficult as to why vectors and linear transformations, although usually represented by an array of numbers or a matrix, are not those arrays but rather entities on their own, as you said agnostic to coordinates.Yes, if they are defined in a way that is agnostic to coordinate systems. It is possible to define tuples that can not have any physical or geometric meaning. I can define the tuple (1,0) in all coordinate systems, but it does not transform at all — it is (1,0) in any coordinate system. It is not a tensor. Tensors can have a physical or geometric meaning that is independent of the choice of coordinate system. The tuple (1,0) defined that way regardless of coordinate system can not have a physical or geometric meaning. There are similar examples for matrices and they can be found throughout mathematics.
Sooo, are you hinting that perhaps the biggest advantage to using "tensors" is the notation?To some extend, yes. Tensors on the other hand are quite variable, same as matrices are. E.g. scalars, vectors and matrices are also tensors. And they build a tensor algebra with a universal property, i.e. many algebras can be realized as quotient algebras of the tensor algebra. So it is the same as with vectors: it all depends on what we use it for. In the end they are simply an arrow, an arrow that serves many, many applications.
Perhaps the biggest difference between vectors, matrices, and linear algebra with "tensors" is the attitude or conception of the users. My simple minded pragmatic definition of a tensor essentially is a matrix using the tensor notation. Matrices are easily visualized, they have a shape and size. Tensors notation considers only one
coefficient at a time, but a lot of them.
(Butt then, eye am knot a reel physicist)
Sooo, are you hinting that perhaps the biggest advantage to using "tensors" is the notation?
This gives tensors the great advantage of being coordinate system agnostic.Yes, but this is similar difficult as to why vectors and linear transformations, although usually represented by an array of numbers or a matrix, are not those arrays but rather entities on their own, as you said agnostic to coordinates. A tensor is in the end merely a continuation of scalar ##rightarrow## vector ##rightarrow## matrix to simply higher dimensions. They often appear as if they were something special, if we speak of stress-energy tensors or curvature tensors. This is as if we associated automatically a force with a vector, or a rotation with a matrix. I often get the impression that physicists use the term tensor but mean a certain example. It's just a multilinear array or transformation – any multilinear transformation, which are already two interpretations of the same thing. The entire co-contra-variant stuff is also an interpretation, and – in my mind – sometimes a bit deliberate.
This cut from Wikipedia shows a motive of using tensors:
"Because they express a relationship between vectors, tensors themselves must be independent of a particular choice of basis. The basis independence of a tensor then takes the form of a covariant and/or contravariant transformation law that relates the array computed in one basis to that computed in another one. "
I believe this might be one of the most important characteristics of tensors for differential geometry and general relativity. (both essentially over my head)
Thanks for taking the time and effort to write this article.I agree that this is the key feature of a tensor. It is an entity that is defined in such a way that its representations in different coordinate systems satisfy the covariant/contravariant transformation rules. Mathematically, a tensor can be considered an equivalence class of coordinate system representations that satisfy the covariant/contravariant transformation rules. This gives tensors the great advantage of being coordinate system agnostic.
This cut from Wikipedia shows a motive of using tensors:
"Because they express a relationship between vectors, tensors themselves must be independent of a particular choice of basis. The basis independence of a tensor then takes the form of a covariant and/or contravariant transformation law that relates the array computed in one basis to that computed in another one. "
I believe this might be one of the most important characteristics of tensors for differential geometry and general relativity. (both essentially over my head)
Thanks for taking the time and effort to write this article.
"A scalar can be viewed as the coordinate of one dimensional vector space, the component of a basis Vector."
Respected Sir,
can you please explain this statement that you made in your answer?Think of the Reals as a vector space over itself. Then any vector/Real number is a multiple of any non-zero number. Generalize this to any other 1D v. space over the Reals.
"A scalar can be viewed as the coordinate of one dimensional vector space, the component of a basis Vector."
Respected Sir,
can you please explain this statement that you made in your answer?If we have a ##1-##dimensional vector space ##V## with a basis vector ##vec{b}##, then all vectors ##vec{v}## can be written ##vec{v}=c cdot vec{b}##. This means ##c## is the scalar, which transforms ##vec{b}## to ##vec{v}##, the coordinate of ##vec{v}## in the basis ##{vec{b}}## and the component of ##vec{v}## with respect to ##vec{b}##. And it constitutes an isomorphism ##c leftrightarrow vec{v}## between the field ##mathbb{F}## and ##V##.
"A scalar can be viewed as the coordinate of one dimensional vector space, the component of a basis Vector."
Respected Sir,
can you please explain this statement that you made in your answer?
An clear exposition of the Physics approach to tensors is in Leonard Susskind's Lectures on General Relativity starting somewhere around minute 40 in lecture 3.
If I understand the point: if one writes a vector in terms of a basis then its coefficients are picked out by the dual basis. So the coefficients are contravariant.
Concerning this point:
Given a linear map between two vector spaces ##L:V →W## then ##L## determines a map of the algebra of tensor products of vectors in ##V## to the algebra of tensor products of vectors in ##W##. This is correspondence is a covariant functor. ##L## also determines a map of the algebra of tensor products of dual vectors in ##W## to the algebra of tensor products of dual vectors in ##V##. This correspondence is a contravariant functor.
One might guess that this is the reason for the terms covariant and contravariant tensor though I do not know the history.
I agree. This would be a natural way to look at it. However, the German Wikipedia does it the other way around and the English speaks of considering ##V## as ##V^{**}## and refers to basis transformations as the origin of terminology. I find this a bit unsatisfactory as motivation but failed to find a good reason for a different convention.This is what Laurent Shwartz writes in "Les Tenseurs" in 1975:
Ces règles sont bien commodes pour les calculs techniques, mais elles ont pour base une erreur historique, qui n'a pas fini de canuler l'humanité pour plusieurs siècles. Elles furent établies à une époque où on manipulait plus les coordonnées que les vecteurs. Elles aboutissent ainsi à appeler contravariant (contra = contre) ce qui est relatif à ##E##, covariant (co = avec) ce qui est relatif à ##E^*## !! Dans tous les raisonnements théoriques utilisant des produits tensoriels (et ils couvrent aujourd'hui toutes les mathématiques), c'est une catastrophe. Un vecteur de ##E## (resp. ##E^*##) est appelé tenseur contravariant (resp. covariant) ! Ce qui est vrai (et c'est de là que vient l'apellation) c'est que le système de coordonnées d'un vecteur (i.e. "le tenseur ##x^i = langle epsilon^i, x rangle##", ##epsilon^i## formant la base duale) est contravariant ; mais, dans les mathématiques modernes, un vecteur est autre chose que le système de ses coordonnées ! Il aurait fallu appeler tenseur covariant un élément de ##E##, tenseur contravariant un élément de ##E^*##, quitte à faire remarquer que les coordonnées varient en sens inverse.which can be translated by:
These rules are very convenient for technical calculations, but they are based on a historical error, which will continue to play a joke on humanity for several centuries. They were established at a time when coordinates were manipulated more than vectors. They results in calling contravariant (contra = against) what is relative to ##E##, covariant (co = with), which is relative to ##E ^ *## !! In every theoretical reasoning using tensorial products (and they cover all mathematics today), it is a catastrophe. A vector of ##E## (respectively ##E ^ *##) is called a contravariant tensor (respectively a covariant tensor)! What is correct (and this is the origin of such a terminology) is that the system of coordinates of a vector (ie, the tensor ##x^i = langle epsilon^i, x rangle##", ##epsilon^i## being the dual basis) is contravariant; But in modern mathematics a vector is something else than the system of its coordinates! An element of ##E## should have been called covariant tensor, an element of ##E ^ *## contravariant tensor, even if we point out that the coordinates vary in the opposite direction.
Isn't this just a matter of convention? If you have a tensor [itex]t[/itex] of type [itex]V otimes V^* otimes V[/itex], anything you want to do with [itex]t[/itex], you can do the analogous thing with the tensor [itex]t'[/itex] of type [itex]V otimes V otimes V^*[/itex]. There is only a notational difficulty, which is indicating which arguments of one tensor are contracted with which other arguments of a different tensor. But the Einstein summation convention makes this explicit. I meant not just for contraction but for describing the general type ( co- and contra- variant) of the tensor; I was wondering if a tensor with mixed components , like ## V otimes V^{*} otimes V otimes V^{*}… ## could always be expressible as ## V otimes V otimes …V^{*} otimes V^{*}…. ## ., though I agree that when contracting the order does not matter. Basically, could we use contraction to show the two above types are equivalent? I am being kind of lazy, let me try it.
Is there a reason why we group together the (contra/co) variant factors? Why not have , e.g., ## T^p_q = V otimes V^{*} otimes V… ## , etc ?Isn't this just a matter of convention? If you have a tensor [itex]t[/itex] of type [itex]V otimes V^* otimes V[/itex], anything you want to do with [itex]t[/itex], you can do the analogous thing with the tensor [itex]t'[/itex] of type [itex]V otimes V otimes V^*[/itex]. There is only a notational difficulty, which is indicating which arguments of one tensor are contracted with which other arguments of a different tensor. But the Einstein summation convention makes this explicit.
I listed my originally intended chapters here:
https://www.physicsforums.com/threads/what-is-a-tensor-comments.917927/#post-5788263
where universality, natural isomorphisms and what else comes to mind considering tensors would have been included, but this tended to became about 40-50 pages and I wasn't really prepared for such a long explanation … And after this debate here, I'm sure that even then there would have been some who thought I left out an essential part or described something differently from what they are used to and so on. Would have been interesting to learn more about the physical part of it, the more as a tensor to me is merely a multilinear product, which only gets interesting if a subspace is factored out. If there only wasn't these coordinate transformations and indices wherever you look. :wideeyed:
I don't know if you mentioned this, but I think another useful perspective here is that the tensor product also defines a map taking a k-linear map into a linear map ( on the tensor product ; let's stick to vector spaces over ## mathbb R ## and maps into the Reals, to keep it simple for now) , so that there is a map taking, e.g., the dot product ( as a bilinear map, i.e., k=2 ) on ## mathbb R^2 times mathbb R^2 ## into a linear map defined on ## mathbb R^2 otimes mathbb R^2 ## ( Into the Reals, in this case ), so we have a map from {## K :V_1 times V_2 times…times V_k ##} to {## L:V_1 otimes V_2 otimes…otimes V_k ##} , where K is a k-linear map and L is linear. This perspective helps me understand things better.
Say we have a map ##V otimes V^* otimes V = V_1 otimes V^* otimes V_2 longrightarrow W##, then it is an element of ##V_1 otimes V^* otimes V_2 otimes W## which could probably be grouped as ##V^* otimes V_1 otimes V_2 otimes W## and we have the original grouping again. I don't know of an example, where the placing of ##V^*## depends on the fact, that it is in between the copies of ##V##. As soon as algebras play a role, we factor their multiplication rules anyway. Or even better in a way such that the contravariance of ##W## is respected.
Perhaps if you consider tensor algebras of ##operatorname{Hom}(V,V^*)## or similar. I would group them pairwise in such a case: all even indexed ##V## and all odd indexed ##V^*##. This is what I really learnt about tensors: it all heavily depends on what you want to do.Maybe we are referring to different things, but if we have a multilinear map defined on , say, ## V otimes V^{*} otimes V ## then the map would be altered, wouldn't it?
Thanks, but aren't there naturally-occurring tensors in which the factors are mixed? What do you then do?Perhaps if you consider tensor algebras of ##operatorname{Hom}(V,V^*)## or similar. I would group them pairwise in such a case: all even indexed ##V## and all odd indexed ##V^*##. This is what I really learnt about tensors: it all heavily depends on what you want to do.
It probably should be noted that when moving from a 2-D matrix to something like a 3-D or 4-D (or n-D) tensor, is a bit like moving from 2-SAT to 3-SAT… most of the interesting things you'd want to do computationally (e.g. numerically finding eigenvalues or singular values) become NP Hard ( E.g. see: https://arxiv.org/pdf/0911.1393.pdf )Yes, interesting, isn't it? This tiny difference between ##2## and ##3## which decides, whether we're too stupid to handle those problems, or whether there is a system immanent difficulty. And lower bounds are generally hard to prove. I know that Strassen lost a bet on ##NP = P##. I've forgotten the exact year, but he thought we would have found out somewhere in the 90's. But I guess he enjoyed the journey in a balloon over the Alps anyway.
The grouping allows a far better handling. There is no advantage in mixing the factors, so why should it be done? Perhaps in case where one considers tensors of ##V = U otimes U^*##. The applications I know are all for low values of ##p,q## and it only matters how the application of a tensor is defined on another object. Formally one could even establish a bijection like the transposition of matrices. But all of this only means more work in writing without any benefits. E.g. Strassen's algorithm can equally be written as ##sum u^*otimes v^* otimes W## or ##sum W otimes u^*otimes v^*##. Only switching ##u^*,v^*## would make a difference, namely between ##Acdot B## and ##B cdot A##.
I once calculated the group of all ##(varphi^*,psi^*,chi)## with ##[X,Y]=chi([varphi(X),psi(Y)])## for all semisimple Lie algebras. Nothing interesting except that ##mathfrak{su}(2)## produced an exception – as usual. But I found a pretty interesting byproduct for non-semisimple Lie algebras. Unfortunately this excludes physics, I guess.Thanks, but aren't there naturally-occurring tensors in which the factors are mixed? What do you then do?
Is there a reason why we group together the (contra/co) variant factors? Why not have , e.g., ## T^p_q = V otimes V^{*} otimes V… ## , etc ?The grouping allows a far better handling. There is no advantage in mixing the factors, so why should it be done? Perhaps in case where one considers tensors of ##V = U otimes U^*##. The applications I know are all for low values of ##p,q## and it only matters how the application of a tensor is defined on another object. Formally one could even establish a bijection like the transposition of matrices. But all of this only means more work in writing without any benefits. E.g. Strassen's algorithm can equally be written as ##sum u^*otimes v^* otimes W## or ##sum W otimes u^*otimes v^*##. Only switching ##u^*,v^*## would make a difference, namely between ##Acdot B## and ##B cdot A##.
I once calculated the group of all ##(varphi^*,psi^*,chi)## with ##[X,Y]=chi([varphi(X),psi(Y)])## for all semisimple Lie algebras. Nothing interesting except that ##mathfrak{su}(2)## produced an exception – as usual. But I found a pretty interesting byproduct for non-semisimple Lie algebras. Unfortunately this excludes physics, I guess.
I liked this article. I am well aware of the proof of correctness of Strassen's algorithm, but had never seen where the idea came from — nice.
It occurs to me that if people are only interested in certain properties of higher rank tensors and they don't want the object to jump off the page, they may be interested in things like Kronecker products or wedge products.
It probably should be noted that when moving from a 2-D matrix to something like a 3-D or 4-D (or n-D) tensor, is a bit like moving from 2-SAT to 3-SAT… most of the interesting things you'd want to do computationally (e.g. numerically finding eigenvalues or singular values) become NP Hard ( E.g. see: https://arxiv.org/pdf/0911.1393.pdf )
I learned about tensors in college – fluids or thermodynamics, maybe, I cannot recall for sure. I "sort of" got it, but later on in life, I came across this video, which I found useful.
One has the isomorphism between ##V## and ##V^{**}##, ##v→v^{**}## ,defined by ##v^{**}(w) = w(v)##.Yes, but AFAIK is not a natural isomorphism, meaning it is not basis-independent. I wonder to what effects/ when this makes a difference.
I don't know if this matters in terms of equating the two, but the isomorphism between ## V , V^{**} ## is not a natural one.One has the isomorphism between ##V## and ##V^{**}##, ##v→v^{**}##, defined by ##v^{**}(w) = w(v)##.
I think I said the same thing. The covariant factors are the tensor products of the vectors, the contravariant are the tensors of the dual vectors. Is there a reason why we group together the (contra/co) variant factors? Why not have , e.g., ## T^p_q = V otimes V^{*} otimes V… ## , etc ?
I agree. This would be a natural way to look at it. However, the German Wikipedia does it the other way around and the English speaks of considering ##V## as ##V^{**}## and refers to basis transformations as the origin of terminology. I find this a bit unsatisfactory as motivation but failed to find a good reason for a different convention.I don't know if this matters in terms of equating the two, but the isomorphism between ## V , V^{**} ## is not a natural one.
I agree. This would be a natural way to look at it. However, the German Wikipedia does it the other way around and the English speaks of considering ##V## as ##V^{**}## and refers to basis transformations as the origin of terminology. I find this a bit unsatisfactory as motivation but failed to find a good reason for a different convention.In Physics a contravariant vector is thought of as a displacement dx. In Mathematics this corresponds to a 1 form and at each point in space this is a dual vector to the vector space of tangent vectors.
In primitive terms one does not think of the tangent space as its double dual.
I think I said the same thing. The covariant factors are the tensor products of the vectors, the contravariant are the tensors of the dual vectors.I agree. This would be a natural way to look at it. However, the German Wikipedia does it the other way around and the English speaks of considering ##V## as ##V^{**}## and refers to basis transformations as the origin of terminology. I find this a bit unsatisfactory as motivation but failed to find a good reason for a different convention.
Yes, but one could as well say ##T_q^p(V) = underbrace{V otimes ldots otimes V}_{p-times} otimes underbrace{V^* otimes ldots otimes V^*}_{q-times}## has ##p## covariant factors ##V## and ##q## contravariant factors ##V^*## and in this source
http://www.math.tu-dresden.de/~timmerma/texte/tensoren2.pdf (see beginning of section 2.1)
it is done. So what are the reasons for one or the other? The fact which are noted first? Are the first ones always considered contravariant? As someone who tends to confuse left and right I was looking for some possibility to remember a convention, one or the other. So I'm still looking for a kind of natural, or if not possible, at least a canonical deduction.I think I said the same thing. The covariant factors are the tensor products of the vectors, the contravariant are the tensors of the dual vectors.
Given a linear map between two vector spaces ##L:V →W## then ##L## determines a map of the algebra of tensor products of vectors in ##V## to the algebra of tensor products of vectors in ##W##. This is correspondence is a covariant functor. ##L## also determines a map of the algebra of tensor products of dual vectors in ##W## to the algebra of tensor products of dual vectors in ##V##. This correspondence is a contravariant functor.
One might guess that this is the reason for the terms covariant and contra-variant tensor though I do not know the history.Yes, but one could as well say ##T_q^p(V) = underbrace{V otimes ldots otimes V}_{p-times} otimes underbrace{V^* otimes ldots otimes V^*}_{q-times}## has ##p## covariant factors ##V## and ##q## contravariant factors ##V^*## and in this source
http://www.math.tu-dresden.de/~timmerma/texte/tensoren2.pdf (see beginning of section 2.1)
it is done. So what are the reasons for one or the other? The fact which are noted first? Are the first ones always considered contravariant? As someone who tends to confuse left and right I was looking for some possibility to remember a convention, one or the other. So I'm still looking for a kind of natural, or if not possible, at least a canonical deduction.
Is there a natural way how the ##V's## come up contravariant and the ## V^{*'}s## covariant? Without coordinate transformations?Given a linear map between two vector spaces ##L:V →W## then ##L## determines a map of the algebra of tensor products of vectors in ##V## to the algebra of tensor products of vectors in ##W##. This is correspondence is a covariant functor. ##L## also determines a map of the algebra of tensor products of dual vectors in ##W## to the algebra of tensor products of dual vectors in ##V##. This correspondence is a contravariant functor.
One might guess that this is the reason for the terms covariant and contra-variant tensor though I do not know the history.
The way that tensors are manipulated implicitly assumes isomorphisms between certain spaces.
If [itex]A[/itex] is a vector space, then [itex]A^*[/itex] is the set of linear functions of type [itex]A rightarrow S[/itex] (where [itex]S[/itex] means "scalar", which can mean real numbers or complex numbers or maybe something else depending on the setting).
The first isomorphism is [itex]A^{**}[/itex] is isomorphic to [itex]A[/itex].
The second isomorphism is [itex]A^* otimes B^*[/itex] is isomorphic to those function of type [itex](A times B) rightarrow S[/itex] that are linear in both arguments.
So this means that a tensor of type [itex]T^p_q[/itex] can be thought of as a linear function that takes [itex]q[/itex] vectors and [itex]p[/itex] covectors and returns a scalar, or as a function that takes [itex]q[/itex] vectors and returns an element of [itex]V otimes V otimes … otimes V[/itex] ([itex]p[/itex] of them), or as a function that takes [itex]p[/itex] covectors and returns an element of [itex]V^* otimes … otimes V^*[/itex] ([itex]p[/itex] of them), etc.Good point; same is the case with Tensor Contraction, i.e., it assumes/makes use of , an isomorphism.
The way that tensors are manipulated implicitly assumes isomorphisms between certain spaces.
If [itex]A[/itex] is a vector space, then [itex]A^*[/itex] is the set of linear functions of type [itex]A rightarrow S[/itex] (where [itex]S[/itex] means "scalar", which can mean real numbers or complex numbers or maybe something else depending on the setting).
The first isomorphism is [itex]A^{**}[/itex] is isomorphic to [itex]A[/itex].
The second isomorphism is [itex]A^* otimes B^*[/itex] is isomorphic to those function of type [itex](A times B) rightarrow S[/itex] that are linear in both arguments.
So this means that a tensor of type [itex]T^p_q[/itex] can be thought of as a linear function that takes [itex]q[/itex] vectors and [itex]p[/itex] covectors and returns a scalar, or as a function that takes [itex]q[/itex] vectors and returns an element of [itex]V otimes V otimes … otimes V[/itex] ([itex]p[/itex] of them), or as a function that takes [itex]p[/itex] covectors and returns an element of [itex]V^* otimes … otimes V^*[/itex] ([itex]p[/itex] of them), etc.
Sorry, was a bit in "defensive mode".No problem.
I was replying to someone else's post.Sorry, was a bit in "defensive mode".
It's the freely generated vector space (module) on the set ##U times V##. The factorization indeed guarantees the multilinearity and the finiteness of sums which could as well be formulated as conditions to hold.I was replying to someone else's post.
I think this is done before the moding out and arranging into equivalence classes is done.It's the freely generated vector space (module) on the set ##U times V##. The factorization indeed guarantees the multilinearity and the finiteness of sums which could as well be formulated as conditions to hold.
If I interpret correctly this sentence says the underlying set of U⊗V is U×V. This is not correct. This works for the direct sum U⊕V but the tensor product is a "bigger" set than U×V. One usual way to encode it is to quotient ##mathbb{R}^{(U times V)}## (the set of finitely-supported functions from U×V to ##mathbb{R}##) by the appropriate equivalence relation. I think this is done before the moding out and arranging into equivalence classes is done.
I thought it would be nice to have a good understanding of what a singleton ## a otimes b ## represents in a tensor product. It is one of these things that I have understood and then forgotten many times over.
I am pretty sure most engineering students will not remember what a homomorphism is without looking it up.Corrected. Thanks.
Perhaps I was mislead regarding the intended audience from the beginning. I am pretty sure most engineering students will not remember what a homomorphism is without looking it up. Certainly a person at B-level cannot be expected to know this?
In the end, I suspect we would give different answers to the question in the title based on our backgrounds and the expected audience. My students would (generally) not prefer me to give them the mathematical explanation, but instead the physical application and interpretation, more to the effect of how I think you would interpret "how can you use tensors in physics?" or "how do I interpret the meaning of a tensor?"Yes, you are right. My goal was really to say "Hey look, a tensor is nothing to be afraid of." and that's why I wrote
Depending on whom you ask, how many room and time there is for an answer, where the emphases lie or what you want to use them for, the answers may vary significantly.And to be honest, I'm bad at basis changes, i.e. frame changes and this whole rising and lowering indices is mathematically completely boring stuff. I first wanted to touch all these questions but I saw, that would need a lot of more space. So I decided to write a simple answer and leave the "several parts" article about tensors for the future. Do you want to know where I gave it up? I tried to get my head around the covariant and contravariant parts. Of course I know what this means in general, but what does it mean here? How is it related? Is there a natural way how the ##V's## come up contravariant and the ## V^{*'}s## covariant? Without coordinate transformations? In a categorial sense, it is again a different situation. And as I've found a source where it was just the other way around, I labeled it "deliberate". Which makes sense, as you can always switch between a vector space and its dual – mathematically. I guess it depends on whether one considers ##operatorname{Hom}(V,V^*)## or ##operatorname{Hom}(V^*,V)##. But if you know a good answer, I really like to hear it.
This must mean I am B-level. :oops::eek::frown:Well, your motivation can't have been to learn what a tensor is. That's for sure. :cool: Maybe you have been curious about another point of view. As I started, I found there are so many of them, that it would be carrying me away more and more (and thus couldn't be used as a short answer anymore). It is as if you start an article "What is a matrix?" by the sentence: "The Killing form is used to classify all simple Lie Groups, which are classical matrix groups. There is nothing special about it, all we need is the natural representation and traces … etc." Could be done this way, why not.
This is the skeleton I originally planned:
subsection*{Covariance and Contravariance}
subsection*{To Rise and to Lower Indices}
subsection*{Natural Isomorphisms and Representations}
subsection*{Tensor Algebra}
section*{Stress Energy Tensor}
section*{Cauchy Stress Tensor}
section*{Metric Tensor}
section*{Curvature Tensor}
section*{The Co-Universal Property}
subsection*{Graßmann Algebras}
subsection*{Clifford Algebras}
subsection*{Lie Algebras}
section*{Tensor Fields}
I think describing ##c(a \otimes b)## from the perspective of maps as the equivalence class of bilinear maps that take the pair (a,b) to c may help understandability for some people.
Perhaps I was mislead regarding the intended audience from the beginning. I am pretty sure most engineering students will not remember what a homomorphism is without looking it up. Certainly a person at B-level cannot be expected to know this?
In the end, I suspect we would give different answers to the question in the title based on our backgrounds and the expected audience. My students would (generally) not prefer me to give them the mathematical explanation, but instead the physical application and interpretation, more to the effect of how I think you would interpret "how can you use tensors in physics?" or "how do I interpret the meaning of a tensor?"
Nobody on an "A" and probably as well on an "I" level reads a text about what a tensor is.This must mean I am B-level. :oops::eek::frown:
Sure, you can represent a tensor by a multidimensional array, but this does not mean that a tensor is a multidimensional array or that a multidimensional array is a tensor. Let us take the case of tensors in ##Votimes V## for definiteness. A basis change in ##V## can be described by a matrix that will tell you how the tensor components transform, but in itself this matrix is not a tensor.You can consider every matrix as a tensor (defining the matrix rank by tensors) or write a tensor in columns, as it is a vector (element of a vector space) in the end. Personally I like to view a tensor product as the solution of a couniversal mapping problem. As I said, I was tempted to write more about the aspect of "How to use a tensor" instead of "What is a tensor" but this would have led to several chapters and the problem "Where to draw the line" were still an open one. Therefore I simply wanted to take away the fears of the term and answer what it is, as I did before in a few threads, where the basic question was about multilinearity and linear algebra and the constituencies of tensors. The intro with the numbers should show that the degree of complexity depends on the complexity of purpose. I simply wanted to shortcut future answers to threads rather than write a book about tensor calculus. That was the main reason for the examples, which can be understood on a very basic level. Otherwise I would have written about the Ricci tensor and tensor fields which I find far more exciting. And I would have started with rings and modules and not with vector spaces. Thus I only mentioned them, because I wanted to keep it short and to keep it easy: an answer for a thread. Nobody on an "A" and probably as well on an "I" level reads a text about what a tensor is.
Let me first say that I think that the Insight is well written in general. However, I must say that I have had a lot of experience with students not grasping what tensors are based on them being introduced as multidimensional arrays. Sure, you can represent a tensor by a multidimensional array, but this does not mean that a tensor is a multidimensional array or that a multidimensional array is a tensor. Let us take the case of tensors in ##Votimes V## for definiteness. A basis change in ##V## can be described by a matrix that will tell you how the tensor components transform, but in itself this matrix is not a tensor.
Furthermore, you can represent a tensor of any rank with a row or column vector – or (in the case of rank > 1) a matrix for that matter (just choose suitable bases). This may even be more natural if you consider tensors as multilinear maps. An example of a rank 4 tensor being used in solid mechanics is the compliance/stiffness tensors that give a linear relation between the stress tensor and the strain tensor (both symmetric rank 2 tensors). This is often represented as a 6×6 matrix using the basis ##vec e_1 otimes vec e_1##, ##vec e_2 otimes vec e_2##, ##vec e_3 otimes vec e_3##, ##vec e_{{1} otimes vec e_{2}}##, ##vec e_{{1} otimes vec e_{3}}##, ##vec e_{{2} otimes vec e_{3}}## for the symmetric rank 2 tensors. In the same language, the stress and strain tensors are described as column matrices with 6 elements.
Great FAQ @fresh_42!
– Students of General Relativity learn about tensors …
– Students of Quantum Mechanics learn about tensors …
– If one wants to discuss tensor products purely mathematically …I know, or at least assumed all this. And I was tempted to explain a lot of these aspects. However, as I recognized that this would lead to at least three or four parts, I concentrated on my initial purpose again, which was to explain what kind of object tensors are, rather than to cover all aspects of their applications. It was meant to answer this basic question which occasionally comes up on PF and I got bored retyping the same stuff over and over again. That's why I've chosen Strassen's algorithm as an example, because it uses linear functionals as well as vectors to form a tensor product on a very basic level, which could easily be followed.
No, this interpretation was of course not intended, rather a quotient of the free linear span of the set ##U times V##.
I added an explanation to close this trapdoor. Thank you.Thank you
If I interpret correctly this sentence says the underlying set of U⊗V is U×V. This is not correct. This works for the direct sum U⊕V but the tensor product is a "bigger" set than U×V. One usual way to encode it is to quotient ##mathbb{R}^{(U times V)}## (the set of finitely-supported functions from U×V to ##mathbb{R}##) by the appropriate equivalence relation.No, this interpretation was of course not intended, rather a quotient of the free linear span of the set ##U times V##.
I added an explanation to close this trapdoor. Thank you.
The tensor product of two 1 dimensional vector spaces is 1 dimensional so it is smaller not bigger than the direct sum. The tensor product tof two 2 dimensional vector spaces is 4 dimensional so this is the the same size as the direct sum not bigger.This is correct but missing the relevant point: that the presentation contains a false statement. The fact that you can indeed find counter examples where the direct sum is bigger than the tensor product does not makes the insight presentation any more correct.
If I interpret correctly this sentence says the underlying set of U⊗V is U×V. This is not correct. This works for the direct sum U⊕V but the tensor product is a "bigger" set than U×V. One usual way to encode it is to quotient ##mathbb{R}^{(U times V)}## (the set of finitely-supported functions from U×V to ##mathbb{R}##) by the appropriate equivalence relation.The tensor product of two 1 dimensional vector spaces is 1 dimensional so it is smaller not bigger than the direct sum. The tensor product tof two 2 dimensional vector spaces is 4 dimensional so this is the the same size as the direct sum not bigger.
– Students of General Relativity learn about tensors from their transformation properties. Tensors are arrays of number assigned to each coordinate system that transform according to certain rules. Arrays that do not transform according to these rules are not tensors. I think that it would be helpful to connect this General Relativity approach to the mathematical approach that you have explained in this Insight.
Also these students need to understand how a metric allows one to pass back and forth between covariant and contra-variant tensors. One might show how this is the same as passing between a vector space and its dual.
– Students of Quantum Mechanics learn about tensors to describe the states of several particles e.g. two entangled electrons. In this case, the mathematical definition is more like the Quantum Mechanics definition but for the Quantum Mechanics student it is also important to understand how linear operators act on tensor products of vector spaces.
– If one wants to discuss tensor products purely mathematically, then one might show how they are defined when the scalars are not in a field but in a commutative ring – or even a non-commutative ring. It is potentially misleading to says that mathematical tensors require a field.
BTW: The tensor product of two three dimensional vector spaces is nine dimensional. The tensor product to two 1 dimensional vector spaces is 1 dimensional.
Definition: A tensor product of vector spaces U⊗V is a vector space structure on the Cartesian product U×V that satisfies …If I interpret correctly this sentence says the underlying set of U⊗V is U×V. This is not correct. This works for the direct sum U⊕V but the tensor product is a "bigger" set than U×V. One usual way to encode it is to quotient ##mathbb{R}^{(U times V)}## (the set of finitely-supported functions from U×V to ##mathbb{R}##) by the appropriate equivalence relation.