Tensors Explained: Scalars, Vectors, Matrices & Math
Table of Contents
Introduction
Let me start with a counter-question. What is a number? Before you laugh, there is more to this question than one might think. A number can be something we use to count or more advanced an element of a field like real numbers. Students might answer that a number is a scalar. This is the appropriate answer when vector spaces are around. But what is a scalar? A scalar can be viewed as the coordinate of a one-dimensional vector space, the component of a basis vector. It means we stretch or compress a vector. But this manipulation is a transformation, a homomorphism, a linear mapping. So the number represents a linear mapping of a one-dimensional vector space. It also transports other numbers to new ones. Thus it is an element of ##\mathbb{R}^*##, the dual space: ##c \mapsto (a \mapsto \langle c,a \rangle)##. Wait! Linear mapping? Aren’t those represented by matrices? Yes, it is a ##1 \times 1## matrix and even a vector itself.
So without any trouble, we have already found that a number is
Different Perspectives on Numbers
- An element of a field, e.g. ##\mathbb{R}##.
- A scalar.
- A coordinate.
- A component.
- A transformation of other numbers, an element of a dual vector space, e.g. ##\mathbb{R}^*##
- A matrix.
- A vector.
Numbers, Vectors and Matrices
As you might have noticed, we can easily generalize these properties to higher dimensions, i.e. arrays of numbers, which we usually call vectors and matrices. I could as well have asked: What is a vector, what is a matrix? We would have found even more answers, as matrices can be used to solve systems of linear equations, some form matrix groups, others play an important role in calculus as Jacobi matrices, and again others are number schemes in stochastic. In the end, they are only two-dimensional arrays of numbers in a rectangular shape. A number is even the one-dimensional special case of the two-dimensional array matrix.
What Is a Tensor?
This sums up the difficulties when we ask: What is a tensor? Depending on whom you ask, how much room and time there is for an answer, where the emphases lie, or what you want to use them for, the answers may vary significantly. In the end, they are only multi-dimensional arrays of numbers in a rectangular shape.1) 2).
$$ \begin{aligned} \begin{bmatrix}2\end{bmatrix} &\qquad \begin{bmatrix}1\\1\end{bmatrix} &\qquad \begin{bmatrix}0 & -1\\ 1 & 0\end{bmatrix} \\[6pt] \text{scalar} &\qquad \text{vector} &\qquad \text{matrix} \\[6pt] – &\qquad (1,0)\ \text{tensor} &\qquad (2,0)\ \text{tensor} \end{aligned} $$
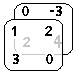
##(3,0)\; tensor##
Intuition and Importance
Many students are used to dealing with scalars (numbers, mass), vectors (arrows, force), and matrices (linear equations, Jacobi-matrix, linear transformations, covariances). The concept of tensors, however, is often new to them at the beginning of their study of physics. Unfortunately, they are as important in physics as scalars, vectors, and matrices are. The good news is, they aren’t any more difficult than the former. They only have more coordinates. This might seem to go to the expense of clarity, but there are methods to deal with it. E.g. a vector also has more coordinates than a scalar. The only difference is, that we can sketch an arrow, whereas sketching an object defined by a cube of numbers is impossible. And as we can do more with matrices, than we can do with scalars, we can do even more with tensors, because a cube of numbers, or even higher dimensional arrays of numbers, can represent a lot more than simple scalars and matrices can. Furthermore, scalars, vectors, and matrices are also tensors. This is already the entire secret about tensors. Everything beyond this point is methods, examples and language, in order to prepare for how tensors can be used to investigate certain objects.
Tensor Definitions
Coordinate and Abstract Views
As variable as the concept of tensors is as variable are possible definitions. In coordinates, a tensor is a multi-dimensional, rectangular scheme of numbers: a single number as a scalar, an array as a vector, a matrix as a linear function, a cube as a bilinear algorithm, and so on. All of them are tensors, as a scalar is a special case of a matrix, all these are special cases of a tensor. The most abstract formulation is: A tensor ##\otimes_\mathbb{F}## is a binary covariant functor that represents a solution for a co-universal mapping problem on the category of vector spaces over a field ##\mathbb{F}## [3]. It is a long way from a scheme of numbers to this categorical definition. To be of practical use, the truth lies – as so often – in between. Numbers don’t mean anything without basis, and categorial terms are useless in an everyday business where coordinates are dominant.
Tensor Product Properties
Definition: A tensor product of vector spaces ##U \otimes V## is a vector space structure on the Cartesian product ##U \times V## that satisfies
$$ \begin{aligned} (u+u’)\otimes v &= u \otimes v + u’ \otimes v\\ u \otimes (v + v’) &= u \otimes v + u \otimes v’\\ \lambda (u\otimes v) &= (\lambda u) \otimes v = u \otimes (\lambda v) \end{aligned} $$
This means a tensor product is a freely generated vector space of all pairs ##(u,v)## that satisfies some additional conditions such as linearity in each argument, i.e. bilinearity, which justifies the name product. Tensors form a vector space as matrices do. The tensor product, however, must not be confused with the direct sum ##U \oplus V## which is of dimension ##\operatorname{dim} U +\operatorname{dim} V## as a basis would be ##\{(u_i,0)\, , \,(0 , v_i)\}##, whereas in a tensor product ##U \otimes V##, all basis vectors ##(u_i,v_j)## are linearly independent and we get the dimension ##\operatorname{dim} U \cdot \operatorname{dim} V##. Tensors can be added and multiplied by scalars. A tensor product is not commutative even if both vector spaces are the same. Now obviously it can be iterated and the vector spaces could as well be dual spaces or algebras. In physics, tensors are often a mixture of several vector spaces and several dual spaces. It also makes sense to sort both kinds as the tensor product isn’t commutative.
Type (p,q) Tensors
Definition: A tensor ##T_q^p## of type ##(p,q)## of ##V## with ##p## contravariant and ##q## covariant components is an element (vector) of
$$ \mathcal{T}(V^p;V^{*}_q) = \underbrace{ V\otimes\ldots\otimes V}_{p\text{-times}}\otimes\underbrace{ V^*\otimes\ldots\otimes V^*}_{q\text{-times}} $$
By (1) this tensor is linear in all its components.
Tensor Examples
Rank and Shape
From a mathematical point of view, it doesn’t matter whether a vector space ##V## or its dual ##V^*## of linear functionals is considered. Both are vector spaces and a tensor product in this context is defined for vector spaces. So we can simply say
- A tensor of rank ##0## is a scalar: ##T^0 \in \mathbb{R}##.
- A tensor of rank ##1## is a vector: ##T^1 = \sum u_i##.
- A tensor of rank ##2## is a matrix: ##T^2 = \sum u_i \otimes v_i##.
- A tensor of rank ##3## is a cube: ##T^3 = \sum u_i \otimes v_i \otimes w_i##.
- A tensor of rank ##4## is a ##4##-cube and we run out of terms for them: ##T^4 = \sum u_i \otimes v_i \otimes w_i \otimes z_i##.
- ##\ldots## etc.
Dyadic Products and Matrices
If we build ##u \otimes v## in coordinates we get a matrix. Say ##u = (u_1,\ldots ,u_m)^\tau## and ##v = (v_1,\ldots , v_n)^\tau##. Then
$$ u \otimes v = u \cdot v^\tau = \begin{bmatrix} u_1v_1 & u_1v_2 & u_1v_3 & \ldots & u_1v_n\\ u_2v_1 & u_2v_2 & u_2v_3 & \ldots & u_2v_n\\ u_3v_1 & u_3v_2 & u_3v_3 & \ldots & u_3v_n\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ u_m v_1 & u_m v_2 & u_m v_3 & \ldots & u_m v_n \end{bmatrix} $$
Higher-order Tensors
Note that this is the usual matrix multiplication, row times column. But here the first factor is ##m## rows of length ##1## and the second factor is ##n## columns of length ##1##. It also means that this matrix is a matrix of rank one since it consists of different multiples of a single row vector ##v^\tau##. To write an arbitrary ##n \times n## matrix ##A## as a tensor, we need ##n## of those dyadic tensors, i.e.
$$ A = \sum_{i=1}^n u_i \otimes v_i $$
A generic “cube” ##u \otimes v \otimes w## will get us a “rank ##1## cube” as different multiples of a rank ##1## matrix stacked to a cube. An arbitrary “cube” would be a sum of these. And this procedure isn’t bounded by dimensions. We can go on and on. The only thing is, that already “cube” was a bit of a crutch to describe a three-dimensional array of numbers and we ran out of words other than tensor. A four-dimensional version (tensor) could be viewed as the tensor product of two matrices, which themselves are tensor products of two vectors and always sums of them.
Strassen Algorithm Example
Let us consider now arbitrary ##2 \times 2## matrices ##M## and order their entries such that we can consider them as vectors because ##\mathbb{M}(2,2)## is a vector space. Say ##(M_{11},M_{12},M_{21},M_{22})##. Then we get in
$$ \begin{aligned} M \cdot N &= \begin{bmatrix} M_{11} & M_{12} \\ M_{21} & M_{22} \end{bmatrix} \cdot \begin{bmatrix} N_{11} & N_{12} \\ N_{21} & N_{22} \end{bmatrix} \\[6pt] &= \begin{bmatrix} M_{11}N_{11}+M_{12}N_{21} & M_{11}N_{12}+M_{12}N_{22} \\ M_{21}N_{11}+M_{22}N_{21} & M_{21}N_{12}+M_{22}N_{22} \end{bmatrix} \\[6pt] &= \left(\sum_{\mu =1}^{7} u_{\mu }^* \otimes v_{\mu }^* \otimes W_{\mu}\right)(M,N) = \sum_{\mu =1}^{7} u_{\mu}^*(M) \cdot v_{\mu}^*(N) \cdot W_{\mu} \\[6pt] &= \bigg( \begin{bmatrix} 1\\0 \\0 \\1 \end{bmatrix}\otimes \begin{bmatrix} 1\\0 \\0 \\1 \end{bmatrix} \otimes \begin{bmatrix} 1\\0 \\0 \\1 \end{bmatrix} + \begin{bmatrix} 0\\0 \\1 \\1 \end{bmatrix}\otimes \begin{bmatrix} 1\\0 \\0 \\0 \end{bmatrix} \otimes \begin{bmatrix} 0\\0 \\1 \\-1 \end{bmatrix} \\ \qquad + \begin{bmatrix} 1\\0 \\0 \\0 \end{bmatrix}\otimes \begin{bmatrix} 0\\1 \\0 \\-1 \end{bmatrix} \otimes \begin{bmatrix} 0\\1 \\0 \\1 \end{bmatrix} + \begin{bmatrix} 0\\0 \\0 \\1 \end{bmatrix}\otimes \begin{bmatrix}-1\\0 \\1 \\0 \end{bmatrix} \otimes \begin{bmatrix} 1\\0 \\1 \\0 \end{bmatrix} \\ \qquad + \begin{bmatrix} 1\\1 \\0 \\0 \end{bmatrix}\otimes \begin{bmatrix} 0\\0 \\0 \\1 \end{bmatrix} \otimes \begin{bmatrix}-1\\1 \\0 \\0 \end{bmatrix} + \begin{bmatrix}-1\\0 \\1 \\0 \end{bmatrix}\otimes \begin{bmatrix} 1\\1 \\0 \\0 \end{bmatrix} \otimes \begin{bmatrix} 0\\0 \\0 \\1 \end{bmatrix} \\ \qquad + \begin{bmatrix} 0\\1 \\0 \\-1 \end{bmatrix}\otimes \begin{bmatrix} 0\\0 \\1 \\1 \end{bmatrix} \otimes \begin{bmatrix} 1\\0 \\0 \\0 \end{bmatrix} \bigg).(M,N) \end{aligned} $$
a matrix multiplication of ##2 \times 2## matrices which only needs seven generic multiplications ##u_{\mu}^*(M) \cdot v_{\mu}^*(N) ## to the expense of more additions. This (bilinear) algorithm is from Volker Strassen ##[1]##. It reduced the “matrix exponent” from ##3## to ##\log_2 7 = 2.807## which means matrix multiplication can be done with ##n^{2.807}## essential multiplications instead of the obvious ##n^3## by simply multiplying rows and columns. The current record holder is an algorithm from François Le Gall (2014) with an upper bound of ##O(n^{2.3728639}) [5]##. For the sake of completeness let me add, that these numbers are true for large ##n## and they start with different values of ##n##. For ##n=2## Strassen’s algorithm is already optimal. One cannot use less than seven multiplications to calculate the product of two ##2 \times 2## matrices. For larger matrices, however, there are algorithms with fewer multiplications. Whether these algorithms can be called efficient or useful is a different discussion. I once have been told that Strassen’s algorithm had been used in cockpit software, but I’m not sure if this is true.
Key Points from the Example
This example shall demonstrate the following points:
- The actual presentation of tensors depends on the choice of basis as well as it does for vectors and matrices.
- Strassen’s algorithm is an easy example of how tensors can be used as mappings to describe certain objects. The set of all those algorithms for this matrix multiplication forms an algebraic variety, i.e. a geometrical object.
- Tensors can be used for various applications, not necessarily only in mathematics and physics, but also in computer science.
- The obvious, here “Matrix multiplication of ##2 \times 2## matrices needs ##8## generic multiplications.” isn’t necessarily the truth. Strassen saved one.
- A tensor itself is a linear combination of let’s say generic tensors of the form ##v_1 \otimes \ldots \otimes v_m##. In the case of ##m=1## one doesn’t speak of tensors, but of vectors instead, although strictly speaking they would be called monads. In case ##m=2## these generic tensors are called dyads and in case ##m=3## triads.
- One cannot simplify the addition of generic tensors, it remains a formal sum. The only exception for multilinear objects is always $$ u_1 \otimes v \otimes w + u_2 \otimes v \otimes w = (u_1 +u_2) \otimes v \otimes w $$ where all but one factor are identical in which case we know it as distributive property.
- Matrix multiplication isn’t commutative. So we are not allowed the swap the ##u_\mu^*## and ##v_\mu^*## in the above example, i.e. a tensor product isn’t commutative either.
- Tensors according to a given basis are number schemes. Which meaning we attach to them depends on our purpose.
Applications in Physics and Algebra
However, these schemes of numbers called tensors can stand for a lot of things: transformations, algorithms, tensor algebras, or tensor fields. They can be used as a construction template for Graßmann algebras, Clifford algebras, or Lie algebras, because of their (co-)universal property. They occur at really many places in physics, e.g. stress-energy tensors, Cauchy stress tensors, metric tensors, or curvature tensors such as the Ricci tensor, just to name a few. Not bad for some numbers ordered in multidimensional cubes. This only reflects, what we’ve already experienced with matrices. As a single object, they are only some numbers in rectangular form. But we use them to solve linear equations as well as to describe the fundamental forces in our universe.
Sources
Sources
- Strassen, V., Gaussian elimination is not optimal, 1969, Numer. Math. (1969) 13: 354. doi:10.1007/BF02165411
- Werner Greub, Linear Algebra, Springer Verlag New York Inc., 1981, GTM 23
https://www.amazon.com/Linear-Algebra-Werner-Greub/dp/8184896336 - Götz Brunner, Homologische Algebra, Bibliografisches Institut AG Zürich, 1973
- Maximillian Ganster, Graz University of Technology, Lecture Notes Summer 2010, Vektoranalysis,
https://www.math.tugraz.at/~ganster/lv_vektoranalysis_ss_10/20_ko-_und_kontravariante_darstellung.pdf François Le Gall, 2014, Powers of Tensors and Fast Matrix Multiplication, https://arxiv.org/abs/1401.7714
Footnotes
##\underline{Footnotes:}##
1) Tensors don’t need to be of the same size in every dimension, i.e. don’t have to be built from vectors of the same dimension, so the examples below are already a special case even though the standard case in the sense that quadratic matrices appear more often than rectangular ones. ##\uparrow##
2) One might call a scalar a (0,0) tensor, but I will leave this up to the logicians. ##\uparrow##






Leave a Reply
Want to join the discussion?Feel free to contribute!