
Scientific Inference: Do We Really Need Induction?
Click for Full Series
Table of Contents
Part 2. “We don’t need no stinkin’ induction” — Sir Karl Popper
The traditional scientific method supposedly employs induction both in the course of forming hypotheses and empirically confirming them. The examples of inductive inference from the previous note—whether the sun will rise tomorrow, or whether the sequence 1,3,5,7,9,… anticipates all odd numbers—were discussed in the context of hypothesis formation. They were simplified illustrations, but there are real-world examples. Take Charles Darwin: it was through his careful study and direct observation of individual animal specimens that he came to discern the hints of a much grander and extensive law of nature. By examining the beak shapes of particular finches in the Galapagos, Darwin was able to induce a wide-ranging principle that applied not only to other species but across eons of time. Incidentally, this is an example of strong induction, as evidenced by the wild success of the theory of evolution by natural selection. There are other great hypotheses, however, that do not share this inductive genealogy: Schrödinger’s non-relativistic wave equation comes to mind, as does Einstein’s relativity theory. In Schrödinger’s case, the equation was the result of a creative, non-logical affair incorporating theoretical aesthetic, bold conjecture, and apparently a skiing holiday in the Swiss Alps; in Einstein’s case, it was a thought experiment that got terribly out of hand.
Surely these ideas came from somewhere; after all, not since Locke introduced the world to empiricism have people actually believed that facts about nature can be known a priori1. Indeed, they come from observations, but not systematically and not without man’s psychological propensity for pattern-seeking or his inborn sense of causal relation. Philosopher of science, Karl Popper, rejected hypothesis-by-induction outright, arguing instead that science progresses not through the steady accumulation of evidence to universals, but instead as a series of conjectures and refutations, of “inventions—conjectures boldly put forward for trial, to be eliminated if they clashed with observations…” that arise “psychologically or genetically a priori, prior to all observational experience.” [1] It’s easy to misinterpret Popper’s statement: he does not literally mean all observation experience, but that precursor experience (“genetically a priori“) from which inductive generalizations are reached. We’ll grant that induction has nothing necessarily to do with the formation of hypotheses and examine instead the main theme of this series: its role in justifying hypotheses.
If we consult again the examples from the last note, they are just as many acts of hypothesis justification as they are examples of hypothesis formation. For example, the observation of a few black jellybeans motivated the hypothesis (if unwisely) that all jellybeans in the jar were black. Equivalently, the observation of a few black jellybeans also constitutes a certain amount of evidence in favor of the proposed hypothesis that all jellybeans in the jar are black. And of course, the comparison of the data with the hypothesis fundamentally involves induction. Schematically, the process of hypothesis testing goes as follows: from hypothesis, [itex]H[/itex], an observable prediction, [itex]O[/itex], is deduced: [itex]H\rightarrow O[/itex]. This prediction will be about a track in a cloud chamber or a fossil in the Cambrian. We then set up an experiment or organize an expedition to test the prediction. To confirm the hypothesis, we must use inductive inference: we generalize the observation and compare it against the hypothesis: [itex]O\rightarrow H[/itex]. Now, if [itex]O[/itex] agrees with the prediction, have we confirmed [itex]H[/itex]? Sadly, no, because [itex]O\rightarrow H[/itex] is not a deductively valid move. It is an example of the logical fallacy of affirming the consequent: the assertion [itex]O\rightarrow H[/itex] does not follow from [itex]H\rightarrow O[/itex] because it is in general possible to find some other hypothesis, say, [itex]H'[/itex], that is also compatible with the observation, [itex]H’\rightarrow O[/itex]. This is the problem of projectability that we just discussed last time: for example, the observation of the numbers [itex]1,3,5,7,9[/itex] agrees with both the hypothesis [itex]x_n=2n+1[/itex] and [itex]x_n=(1−2n-1)(3−2n-1)(5−2n-1)(7−2n-1)(9−2n-1)+2n+1[/itex].
Sometimes we can legally get away with affirming the consequent if we know that a particular hypothesis describes all the necessary and sufficient conditions for the observation. The only way to know is to do comprehensive experiments that account for all the relevant conditions, a feat that is seldom possible in practice: as Figure 1 shows, the data might fail to reveal the causal relationships between the experimental conditions and the observations, leaving multiple hypotheses in the running2. In general, though, certain and exact confirmation of unique hypotheses is not possible.
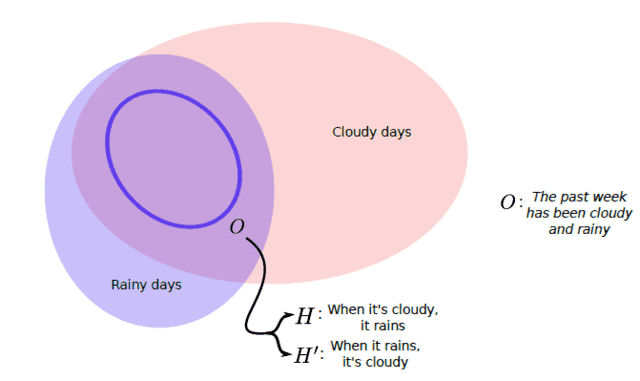
Fig 1. The danger of working from observation, [itex]O[/itex], to hypothesis, [itex]H[/itex]. Given the observation (circled in blue) that the past week as been both cloudy and rainy, the causal relationship between rain and clouds is unclear—it is not known whether clouds are a necessary or sufficient condition for rain. The observation is therefore compatible with at least two hypotheses: [itex]H[/itex], which asserts that clouds are a sufficient condition for rain, and [itex]H'[/itex], which asserts that clouds are a necessary condition.
In the 1930s, Karl Popper was moved to abandon confirmation as an instrument of scientific discovery because he did not accept the inductive scaffolding on which it is built. He recognized an important asymmetry between the acts of confirmation and refutation: while it is impossible to verify a universal statement by observing singular instances, universal statements can be contradicted by individual observations. Take the prototypical sample hypothesis that all swans are white—though the number of swans is arguably finite, we cannot search the whole world over in an attempt to verify this hypothesis (and if we could, it would not result in a predictive theory). We can, however, falsify it, swiftly and assuredly by observing just a single black swan. Unlike confirmation, the falsification of hypotheses is a deductively-sound procedure employing the classical rule of modus tollens: if [itex]H\rightarrow O[/itex], then [itex]\overline{O}\rightarrow \overline{H}[/itex] (where [itex]\overline{O}[/itex] is read “not [itex]O[/itex]”). While in practice statistical limitations might require several disconfirming trials before a hypothesis or theory is discarded, sometimes the evidence is resounding: for example, the discovery of the cosmic microwave background in 1965 decapitated Hoyle’s steady-state universe model
in one fell swoop. By proposing falsification as the means of testing hypotheses, Popper sought to establish a logically valid, induction-free approach to the justification of all scientific proposals based on the simple maxim: “it must be possible for an empirical scientific system to be refuted by experience” [2].
Attempts at falsification: The p-value catastrophe
Falsification is the presumed mode of inference employed by much of contemporary science based on frequentist, or classical, statistics. The weapon of choice is the most well-worn instrument of statistical terror ever to be foisted upon the scientific process—the p-value. Suppose we wish to test some hypothesis, [itex]H_0[/itex]. The subscript ‘0’ indicates that this hypothesis generally refers to some fiducial model, perhaps one for which the effect we’re seeking is absent. In this case, it is appropriately called the null hypothesis, and the purpose of the p-value is to determine the agreement between the observed data, [itex]O[/itex], and the null hypothesis, [itex]H_0[/itex], when there are other possible explanatory hypotheses. Specifically, it provides the probability that we would observe the data [itex]O[/itex] under the assumption that [itex]H_0[/itex] is correct, [itex]p(O|H_0)[/itex]3. A small p-value, say less than 0.05, means that there is a smaller than 5% chance that we would have measured the data [itex]O[/itex] given that [itex]H_0[/itex] is true. In other words, [itex]H_0[/itex] is correct, and the tension with the data arises instead due to chance (whether it’s from noise in the measuring device or some fundamental uncertainty of the physical process being measured.) Often, however, in the statistical parlance one reads that the p-value as the probability of “falsely rejecting the null hypothesis”. This agrees with our understanding of the p-value as the chance of a statistical fluke, but we are actually in no way licensed to reject, or falsify, the null hypothesis if the p-value happens to be small.
Let’s see what goes wrong when we use p-values to make inferences. Upon making observation [itex]O[/itex], we compute [itex]p(O|H_0)[/itex], the probability that we measure [itex]O[/itex] given the truth of [itex]H_0[/itex]. Suppose the p-value is found to be [itex]<0.05[/itex]. Next, we equate [itex]p(O|H_0)[/itex] with [itex]p(H_0|O)[/itex], the probability of the truth of [itex]H_0[/itex] given the observation, [itex]O[/itex]. Then, we conclude [itex]p(\overline{H}_0|O) = 1 – p(H_0|O)[/itex], which asserts that some alternative hypothesis (or group of hypotheses), [itex]\overline{H}_0[/itex], which is typically a model (or group of models) that supports the observed effect, is correct at [itex]95\%[/itex] confidence. Can you spot the error? In the very first step we took [itex]p(O|H_0) = p(H_0|O)[/itex]. This is wrong—it’s called the fallacy of the transposed conditional. It’s not as bad as affirming the consequent (for which we’d always have [itex]p(O|H_0)=p(H_0|O) = 1[/itex]), but it can really get us into trouble. An especially striking example of this confusion is discouragingly called the prosecutor’s fallacy because it has been used by the prosecution in criminal court to argue for the guilt of the defendant: the probability of getting certain evidence, say DNA evidence ([itex]E[/itex]), given the innocence ([itex]I[/itex]) of the defendant, [itex]P(E|I)[/itex] (which is typically low) is equated with the probability of innocence given the evidence, [itex]p(I|E)[/itex] (which is then likewise low). What is neglected here is the chance that the defendant is innocent in the first place before the evidence is brought. Catastrophic when misused in the court of law, it is also tragic that it provides the statistical foundation of many important scientific results, from drug efficacy to climate change.
In practice, we see that the p-value is not really about falsification: it’s used ostensibly to confirm a hypothesis alternative to the null hypothesis, which it must falsify in the course of doing business. And we must commit a logical fallacy in order to accomplish this inference. Popper would not be pleased, nor would anyone seeking a coherent scientific inference. P-value catastrophe aside, Popper’s model of falsification still has its dissenters. After all, what good is the scientific method if it can only tell us when we get stuff wrong?
Corroboration without induction?
Popular objections to Popper’s program tend to center around the perceived negativity associated with the act of falsification; call it a psychological aversion to failure. More practically, the concern is that science should not be about what doesn’t work—how can we hope to increase our knowledge of the world if we cannot confirm, or verify, scientific hypotheses? Shouldn’t science be a constructive, rather than destructive, pursuit? According to Popper, the only tenable position is that all of our theories are basically wrong, awaiting falsification. Importantly, though, Popper views the cycle of conjecture and refutation as generative, as one that puts scientific hypotheses through a kind of optimization process in order to develop theories that, though ultimately incorrect, are the very best possible prototype of the truth: “Theories are nets cast to catch what we call ‘the world’: to rationalize, to explain, to master it. We endeavor to make the mesh ever finer and finer.” [2] This optimization process must be a relentless, vigorous assault on all hypotheses and scientific proposals bent on striking down those that miss the mark, weeding out the “unfit” hypotheses by “exposing them all to the fiercest struggle for survival.”
While Popper advocates for falsification, those hypotheses that escape it are not all considered equal. Those that pass the most strenuous attempts at falsification are in some sense preferred and were said by Popper to be corroborated. Corroboration is not an absolute condition: a theory is either more corroborated than a competitor, or new data can further corroborate an existing theory. Corroboration is essentially a measure of the testability, or falsifiability, of a hypothesis relative to alternatives. And testability, Popper argues, is logically related to the empirical content of the theory: “the more a theory forbids, the more it says about the world of experience.” What this means is that theories with more universal or precise statements have greater testability because there are more opportunities for a misstep, more places for them to go wrong.
But when all is said and done and we end up with our most stream-lined, best-fitting model, there is a strong sense that it has been given positive support by the data. Is this just an illusion? Has Popper really, truly done away with confirmation? I don’t think so. Let’s revisit the “experiment” conducted in Figure 1, but suppose we’ve collected more data. Furthermore, our experiment has been improved so that we can also measure the existence of lightning,
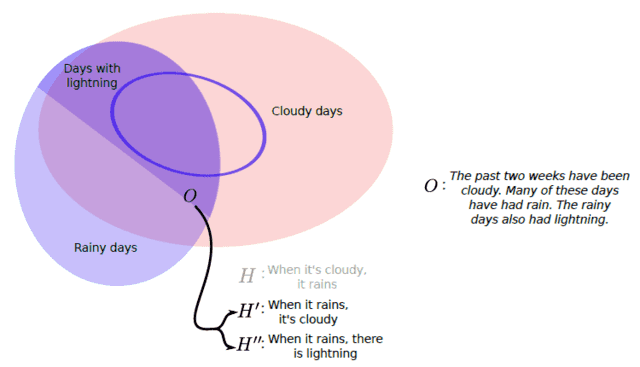
Fig 2. An illustration of corroboration. Both [itex]H'[/itex] and [itex]H”[/itex] are consistent with the observation, but [itex]H”[/itex] is more prone to falsification than [itex]H'[/itex] because its “predictive range” is smaller. Hypothesis [itex]H”[/itex] is more corroborated according to Popper.
Our dataset is such that we’ve observed some cloudy days without rain, falsifying hypothesis [itex]H[/itex], and it just so happens that every rainy day also had lightning. This latter observation supports a new hypothesis [itex]H”[/itex], that whenever it rains, there is lightning. On the question of causality, it is an alternative to [itex]H'[/itex]: that whenever it rains, there are clouds. Now, while both [itex]H'[/itex] and [itex]H”[/itex] are consistent with the data, we see [itex]H”[/itex] is more easy to falsify because its “predictive range” is smaller, in fact contained within, that of [itex]H'[/itex]. In other words, fewer observations are needed to falsify [itex]H”[/itex] than [itex]H'[/itex]. [itex]H”[/itex] is therefore more corroborated than [itex]H'[/itex] and by this we must mean that it gets more things right than [itex]H'[/itex]. Popper called this tendency towards truth verisimilitude [1] and, while it is meant to apply to ultimately false hypotheses, it is an accounting of correct statements made by the hypothesis, i.e. it is an accounting of the degree of support that the data lends to the hypothesis. This suggests a tempered view of confirmation, one that surrenders certainty for degrees of confidence instead, in line with an inductive mode of justification. While Popper might wish to view the hypothesis that passes experimental muster as ultimately false and merely awaiting rejection, until that time we consider it the most successful generalization of observed phenomena. Popper discounts the validity of the latter view, but what else is corroboration if not tentative acceptance? Both refer to the same logical relation between evidence and hypothesis. My impression is that, despite Popper’s attempts to exorcise him, Hume’s specter still lurks in the idea of corroboration. Next time, we’ll see about developing a theory of confirmation.
Read on to Part 3: Balancing Predictive Success with Falsifiability
References and Footnotes
[1] Conjectures and Refutations: The Growth of Scientific Knowledge, Karl Popper, Routledge (1963).
[2] The Logic of Scientific Discovery, Karl Popper, Routledge (1934).
1Think babies born with electrodynamics already in their heads. back
2Charlatans and conspiracy theorists alike adore this kind of situation because they believe it gives faith healing and UFO abductions equal room on the stage of potential explanations for a given piece of evidence. It doesn’t, and we’ll see why shortly. back
3The notation [itex]p(x|y)[/itex] should be read “the probability of [itex]x[/itex] given that [itex]y[/itex] is true.” back
After a brief stint as a cosmologist, I wound up at the interface of data science and cybersecurity, thinking about ways of applying machine learning and big data analytics to detect cyber attacks. I still enjoy thinking and learning about the universe, and Physics Forums has been a great way to stay engaged. I like to read and write about science, computers, and sometimes, against my better judgment, philosophy. I like beer, cats, books, and one spectacular woman who puts up with my tomfoolery.



I found this article very informative. Keep going for good work
“Just an observation: The type of “universal laws” that are always used in discussing induction or falsifiability almost never become part of a scientific theory. What I mean is that nobody just notices a correlation and proposes it as a universal law: “Hey! Every dachshund I’ve ever known has a name starting with the letter S. Maybe that’s a universal law of physics!””
Agreed. This is why the discussion is focused on hypothesis testing rather than hypothesis formation.
“Does that necessarily mean the model is incorrect? As far as I’m aware, there is no such thing as a perfect model that takes everything into account. And we all know GR is incomplete. So any model is incorrect then?”
I would say that almost any model that we are currently using is not only wrong, but we know that it’s wrong. But I suppose there is a distinction between being completely wrong, and being “in the right ballpark”. For example, when we compute the energy levels of hydrogen using the nonrelativistic Schrodinger equation, we know the derivation isn’t actually correct, because it leaves out relativity, and pair creation, and electron spin, and weak interactions, and GR and so forth. But we expect that taking into account those other things will make a small change, and won’t completely overturn how we understand hydrogen atoms.
“Well, in some cases, we know that a model is incorrect (because it ignores relativity, for example), but it still makes predictions that are good enough for practical purposes.”
Does that necessarily mean the model is incorrect? As far as I’m aware, there is no such thing as a perfect model that takes everything into account. And we all know GR is incomplete. So any model is incorrect then?
Just an observation: The type of “universal laws” that are always used in discussing induction or falsifiability almost never become part of a scientific theory. What I mean is that nobody just notices a correlation and proposes it as a universal law: “Hey! Every dachshund I’ve ever known has a name starting with the letter S. Maybe that’s a universal law of physics!” When Newton proposed his law of universal gravitation, he didn’t generalize from lots of measurements of the force between objects. Instead, his proposed law of gravitation was a model or hypothesis that allowed him to derive a whole bunch of other facts–namely, the shapes and periods of orbits of planets, as well as the fact that objects drop to the ground when released.
There are certainly cases where people just notice repeated patterns and propose a law that generalizes from those patterns. For example, the wavelengths of light emitted by hydrogen atoms was found to be given by something like [itex]frac{1}{lambda} propto frac{1}{m^2} – frac{1}{n^2}[/itex] where [itex]m[/itex] and [itex]n[/itex] are integers, and [itex]n > m[/itex]. But it wasn’t really taken as a “law of physics”, but as a regularity that needed to be explained by physics (and the explanation turned out to be quantum mechanics).
“If they give correct results, why are the ideas incorrect then?”
Well, in some cases, we know that a model is incorrect (because it ignores relativity, for example), but it still makes predictions that are good enough for practical purposes.
The problem with ”while it is impossible to verify a universal statement by observing singular instances, universal statements can be contradicted by individual observations” is that what is a falsification is not well-defined. If a first year student falsifies Hooke’s law through his experimental analysis nobody cares. And falsifications of statistical laws are uncertain by the means with which statistics is created and analyzed. Thus falsification has the same somewhat subjective status as verification: We can never be sure, once the laws are allowed to be imprecise in the slightest – which most modern physics laws are.
”
It is quite common for incorrect ideas to give correct results.”
If they give correct results, why are the ideas incorrect then?
In simplified form:
You think something interesting is happening. So you collect data.
Assume that nothing of interest is happening. How likely are you to have gotten such data in this case by pure chance? If it is unlikely, then that gives support to your idea that something interesting is happening.
If someone else gets the same result, then that is further support. And so on. If they get the same result by a different method, that is even better. This is called consilience.
It doesn’t mean that your idea is correct, just that it is consistent with experiment. Not the same thing, but it DOES show that your idea has predictive power. In science that matters a lot. I’d say it is the main purpose of scientific theory: to predict what will happen in such-and-such a situation. Explaining why it happens is definitely secondary.
It is quite common for incorrect ideas to give correct results. Indeed, it is very common for theories known incorrect to be used. Incorrect theories may be convenient and good enough for the purpose at hand, especially if they are much simpler than the correct theory.
“A nice article!
One mistake I found:
That value would by tiny nearly everywhere (what is the probability to observe exactly 425435524 radioactive decays within some timespan, for any relevant hypothesis?). You need the probability to observe “O or something that deviates even more from the expectation based on H[sub]0[/sub]” (which you used in the following text) or a ratio of probabilities for different hypotheses.”
Yeah, thanks. [itex]p(O|H_0)[/itex] is a distribution over [itex]O[/itex]. I’ll reword that!
A nice article!
One mistake I found:
[quote]Specifically, it provides the probability that we would observe the data O under the assumption that H[sub]0[/sub] is correct, p(O|H[sub]0[/sub])[/quote]That value would by tiny nearly everywhere (what is the probability to observe exactly 425435524 radioactive decays within some timespan, for any relevant hypothesis?). You need the probability to observe “O or something that deviates even more from the expectation based on H[sub]0[/sub]” (which you used in the following text) or a ratio of probabilities for different hypotheses.
I found this article very informative. Keep going for good work
The problem with ''while it is impossible to verify a universal statement by observing singular instances, universal statements can be contradicted by individual observations'' is that what is a falsification is not well-defined. If a first year student falsifies Hooke's law through his experimental analysis nobody cares. And falsifications of statistical laws are uncertain by the means with which statistics is created and analyzed. Thus falsification has the same somewhat subjective status as verification: We can never be sure, once the laws are allowed to be imprecise in the slightest – which most modern physics laws are.
In simplified form:You think something interesting is happening. So you collect data.Assume that nothing of interest is happening. How likely are you to have gotten such data in this case by pure chance? If it is unlikely, then that gives support to your idea that something interesting is happening. If someone else gets the same result, then that is further support. And so on. It doesn't mean that your idea is correct, just that it is consistent with experiment. Not the same thing, but it DOES show that your idea has predictive power. In science that matters a lot. It is quite common for incorrect ideas to give correct results. Indeed, it is very common for theories known incorrect to be used. Incorrect theories may be convenient and good enough for the purpose at hand, especially if they are much simpler than the correct theory.