
An Intro to AVX-512 Assembly Programming
Table of Contents
History
In 1998, the Intel Corporation released processors that supported SIMD (single instruction, multiple data) instructions, enabling processors to carry out multiple arithmetic operations using one instruction. This technology was a first step toward parallelization at the instruction level. The technology, SSE (Streaming SIMD Extensions), made it possible to perform arithmetic operations on four pairs of 32-bit floating point numbers at a time, using a set of 16 128-bit registers, named XMM0 through XMM15. Since then, Intel has expanded its offering, releasing SSE2 in 1999, SSE3 in 2004, and several other versions, each with support for more instructions.
In 2011, Intel released AVX (Advanced Vector eXtensions), increasing the sizes of the registers to 256 bits (YMM0 through YMM15). For backward compatibility with SSE, the lower 128 bits of a YMM register is an XMM register with the same numeric suffix. With AVX, programs can process eight pairs of 32-bit float numbers or four pairs of 64-bit double numbers at a time. Two years later, in 2013, Intel released AVX-2, adding support for integer types as well as the floating point types.
The culmination of this string of technologies is Intel’s AVX-512 instruction set, which doubles the number of registers to 32, and doubles the size of each register to 512 bits. The AVX-512 registers are named ZMM1 through ZMM31. The lower 256 bits of each ZMM register is a YMM register; the lower 128 bits of a ZMM register is an XMM register. This instruction set is currently available only on Intel Xeon Phi processors, Intel Xeon Scalable processors, and some Core-X processors. Advanced Micro Devices (AMD) does not support AVX-512at this time.
Why This Article?
One goal for writing this Insights article it to provide additional information about the new AVX-512 technology. Although Intel provides documentation for its entire instruction set (see https://software.intel.com/en-us/articles/intel-sdm#specification), the documentation is terse and extremely sparse on examples. You can find a few examples online, but examples of AVX-512 instructions are difficult to find and few in number.
Another goal in this and subsequent articles in this series, is to highlight some interesting features of the AVX-512 instruction set, especially those that have not been adequately documented.
An Example
Here’s a fairly simple example of adding two 16-element arrays of type float, using a single instruction. After performing the addition, the program stores the results in a destination array. The project is implemented as mixed-language program, with a C++ main function that calls an Intel x86 assembly subroutine. This is a complete example, but you will need to do some additional work to turn this into a running program. If you are interested in the details, send me a private message. Also, this program must be run on a computer that supports the basic AVX-512 instructions.
Here’s the C++ portion:
// Driver.cpp - Use AVX512 instructions to add two arrays.
#include <iostream>
using std::cout;
using std::endl;
// Prototypes
extern "C" void AddArrays(float Dest[], float Arr1[], float Arr2[]);
void PrintArray(float[], int count);
// Data is aligned to 64-byte boundaries
float __declspec(align(64)) Array1[] = // First source array
{ 1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12,
13, 14, 15, 16 };
float __declspec(align(64)) Array2[] = // Second source array
{ 2, 4, 6, 8,
3, 6, 9, 12,
4, 8, 12, 16,
5, 10, 15, 20};
float __declspec(align(64)) Dest[16]; // Destination array
int main()
{
AddArrays(Dest, Array1, Array2); // Call the assembly routine
PrintArray(Dest, 16);
}
void PrintArray(float Arr[], int count)
{
for (int i = 0; i < count; i++) {
cout << Arr[i] << '\t';
}And here’s the assembly code:
.code AddArrays PROC C ; Prototype: extern "C" void AddArrays(float Dest[], float Arr1[], float Arr2[]); ; Parameters: ; Dest - Address of the start of the destination array, in RCX ; Arr1 - Address of the first source array, in RDX ; Arr2 - Address of the second source array, in R8 ; Returns nothing ; Prologue push rdi ; RDI is a non-volatile register, so save it. sub rsp, 20h ; Allocate a stack frame of 20 bytes mov rdi, rsp vzeroall ; Main body of routine vmovaps zmm0, zmmword ptr [rdx] ; Load the first source array vmovaps zmm1, zmmword ptr [r8] ; Load the second source array vaddps zmm2, zmm0, zmm1 ; Add the two arrays vmovaps zmmword ptr[rcx], zmm2 ; Store the array sum ; Epilogue add rsp, 20h ; Adjust the stack back to original state pop rdi ; Restore RDI ret AddArrays ENDP END
The Prologue and Epilogue parts are boilerplate that is required for 64-bit assembly procedures. The part that’s of interest to us is the four lines that make up the main body of the routine.
vmovaps zmm0, zmmword ptr [rdx] ; Load the first source array vmovaps zmm1, zmmword ptr [r8] ; Load the second source array vaddps zmm2, zmm0, zmm1 ; Add the two arrays vmovaps zmmword ptr[rcx], zmm2 ; Store the array sum
Although this names of these instructions might seem like gibberish, the prefixes and suffixes provide a lot of information about the instructions:
- v – vector instruction — operands are vectors
- mov – move
- a – aligned — the data is aligned on a 64-byte boundary
- ps – packed single — the data consists of packed single-precision values
The first vmovaps instruction moves (copies) the 16 float values that start at the address in the RDX to the ZMM0 register. The second vmovaps is similar, copying the 16 float values that start at the address in the R8 to ZMM1.
The vaddps instruction adds the 16 float values in the ZMM0 register to those in ZMM 1, storing the results in register ZMM 2. The following figure shows this operation.
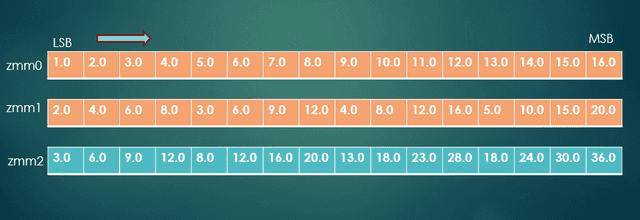
Add 16 pairs of floats
The fourth instruction, vmovaps, copies the 16 sums in ZMM2 to the memory location in register RCX.
In the next installment here, learn how AVX-512 can be used to significantly boost program performance by eliminating “if – then” decision structures. The program I’ll show runs in 1/3 of the time that it takes for its fully optimized C++ equivalent.
Former college mathematics professor for 19 years where I also taught a variety of programming languages, including Fortran, Modula-2, C, and C++. Former technical writer for 15 years at a large software firm headquartered in Redmond, WA. Current associate faculty at a nearby community college, teaching classes in C++ and computer architecture/assembly language.
I enjoy traipsing around off-trail in Olympic National Park and the North Cascades and elsewhere, as well as riding and tinkering with my four motorcycles.






I’m a java developer so that’s why we see those tips in Netbeans as part of the javadoc builtin comments.
will this technology be integrated into Machine Learning applicationsIt occurred to me later that one of the parts of AVX-512 is VNNI, or Vector Neural Network Instructions. It isn't here now, but is slated to be released with the Ice Lake microarchitecture, the 10th gen Core architecture. The release is slated for sometime this year or next.
There's also another part, GFNI, Galois Field New Instructions, that are also tied to the Ice Lake microarchitecture.
At this point, there are 18 separate subsets of the AVX-512 instruction set, not all of which have been released just yet. My new computer, with its Xeon Silver 10-core processor, supports 5 of those subsets.
where little api help tips pop upLOL! There are zero API help tips that pop up in my VS IDE. Maybe the Intel C/C++ compiler has them, or maybe not – don't know 'cause I don't have that compiler. I'm reasonably sure they don't pop up in the Gnu compiler, either. That's why I keep the PDF of the Intel Software Developer's Manual open when I'm writing that code.
I usually start with example code in Netbeans where little api help tips pop up. Only when I hit a bigger issue do I need to delve into the reference docs. It’s coding on the edge of a precipice.
So true, REAL programmers don't read either until they have a problem with their code, if ever.But if you're working with an API that you aren't intimately familiar with, you need to have the API docs very handy.
In the next installment, I'll look at how you can go through a fairly large array of signed numbers, separating out the positive and negative values, and generating totals for each, without using any kind of decision control structures (i.e., no if statements).
Coming Real Soon…
So true, REAL programmers don't read either until they have a problem with their code, if ever.
Very cool, will this technology be integrated into Machine Learning applications as it seems its geared for matrix operations doing parallel adds like that.No idea — I don't know much of anything about machine learning or neural network algorithms or the like. If they involve working with matrices, then this stuff is applicable.
Also I found some videos on Youtube covering the topic in more detail for those of us who are reading challenged.This article is the first in a series of five or more. What I covered in the first article is a bit of background history and a very simple example, for which lots of documentation and examples already exist. In the next few articles I plan to talk about other AVX-512 instructions for which 1) the Intel documentation is very minimal, and 2) there are no usage examples online (if there are any, I couldn't find them after long searches), let alone videos.
"Real programmers don't need no stinkin' videos!" :oldbiggrin:
Very cool, will this technology be integrated into Machine Learning applications as it seems its geared for matrix operations doing parallel adds like that.
Also I found some videos on Youtube covering the topic in more detail for those of us who are reading challenged.
Very cool subject. Thanks! :smile: