AVX-512 Assembly Programming: Opmask Registers for Conditional Arithmetic Conclusion
In the first part of this article (AVX-512 Assembly Programing – Opmask Registers for Conditional Arithmetic), we looked at how opmask registers can be used to perform conditional arithmetic. That article ended with two 512-bit ZMM registers that each contained 16 integer values. One of the registers contained 16 partial sums of the positive numbers in the array, and the other contained 16 partial sums of the negative values in the array. To complete our task we need to add each set of 16 values to get the sums of the positive and negative numbers. Unfortunately, there is no Intel instruction to add all of the values in an AVX-512 register. For that matter, there are no instructions to add all the values in either a 256-bit YMM register or a 128-bit XMM register. However, the earlier AVX and AVX2 instruction sets include instructions to perform what is called horizontal addition on XMM and YMM registers, respectively. This mechanism adds pairs of adjacent numbers, so to add all 16 numbers in a ZMM register, we’ll need to apply horizontal addition numerous times.
Table of Contents
Horizontal Addition
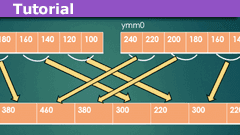
A good way to explain this process is by seeing how the affected registers change, step by step. As an example, suppose that ZMM0 contains the four-byte integer (DWORD) values as shown in Fig. 1. Just as a check, these numbers add up to 1360, so if the computer gives another result, there’s a problem in our code.

Fig. 1 – ZMM0 is initialized with 16 DWORD (int) values
Splitting a Register into Two Halves
The horizontal addition instructions work only on XMM (16 byte) or YMM (32 byte) registers, so we need to split ZMM0 into two YMM registers, as shown in Fig. 2. We can split it into a lower half, which is YMM0. (The lower 256 bits of registers ZMM0 through ZMM15 is a YMM register with the same numeric suffix.) The upper half of ZMM0 can be extracted and inserted into YMM1. This is done using the instruction vextracti32x8 ymm1, zmm0, 1. The number 1 in this instruction indicates that we want the upper 256 bits; a value of 0 would mean to extract the lower 256 bits. The “i32x8” suffix on the instruction was chosen to reflect that fact that we’re extracting 8 32-bit integer values.
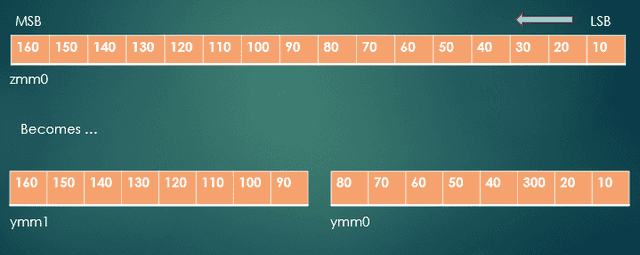
Fig. 2 – ZMM0 split into YMM0 and YMM1
The next step is to add YMM0 and YMM1, storing the sum back into YMM0. We can do this using vpaddd ymm0, ymm0, ymm1. As mentioned in the previous article, we’re adding vectors of packed dword quantities.
First Horizontal Addition
Next, we’ll use horizontal addition, as shown in Fig. 3. Here the instruction is vphaddd ymm0, ymm0, ymm0. The name of this instruction indicates that it does horizontal addition on vectors of packed dwords. Notice how pairs of numbers in either source register are added and stored in the destination register. Also notice that the eight values in the destination (at bottom in the figure)register are really duplicates of only four values.
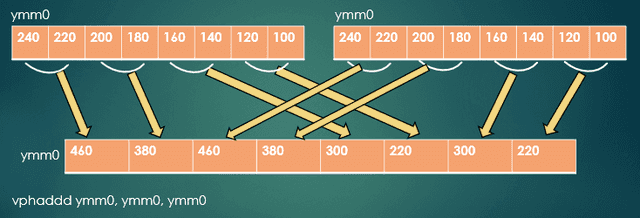
Fig. 3 – How horizontal addition works
Swap the Middle QWORDs
If we reorder the four DWORDs in the middle (the middle quadwords, or QWORDs), all four distinct values will be in the lower half of YMM0. Fig. 4 shows this step. Doing this leaves the four partial sums duplicated in the lower and upper halves of YMM0. Keep in mind that the lower half of YMM0 is also called XMM0. The instruction vpermq ymm0, ymm0, 0d8h does the swap for us, but requires a bit of explanation. The literal 0d8h is the hexadecimal representation of the base-2 value 1101 1000. If we write this as 11 01 10 00 (binary), or 3 1 2 0, this tells the vpermq instruction to leave the QWORD values at index 0 and 3 alone, but to swap the positions of the QWORD values at indexes 1 and 2. If you didn’t notice, the ‘q’ suffix in vpermq means that it operates on QWORD quantities.

Fig. 4 – Permute the QWORDs at indexes 1 and 2
Second Horizontal Addition
After the permutation operation, we have the four partial sums in the lower half of YMM0; that is, in XMM0. The upper half of YMM0 contains that same set of four values, so we can ignore them. Next, as shown in Fig. 5, we’ll do another horizontal addition, this time using vphaddd xmm0, xmm0, xmm0. At this point, we’re almost done, with two partial sums in both the lower and upper halves of XMM0. One more addition should get us the sum we want.
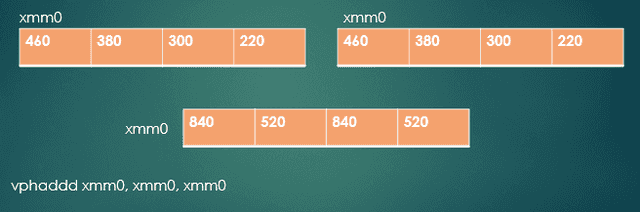
Fig. 5 – Horizontal addition of XMM registers
Third Horizontal Addition
Fig. 6 shows the result of one last horizontal addition, again using vphaddd xmm0, xmm0, xmm0. This leaves us with our answer — 1360 — in all four slots of XMM0.

Fig. 6 – The final horizontal addition
All that’s left is to extract the lowest DWORD (four bytes) from XMM0, which we can do using vpextrd eax, xmm0, 0. This instruction extracts the DWORD at index 0 in XMM0, and stores it in the EAX general purpose register.
Obviously, this is a lot of work just to add up a few numbers. The Intel Software Developer’s Manual shows how the various horizontal addition instructions work, but doesn’t give any insight as to how you would add all the values in one of the XMM or YMM registers. The technique laid out here is what I’ve been able to come up with.
Run-time Comparisons
The table shows comparisons of eight program runs using an array of 12,800 randomly generated integers. In four of the runs, the compiler did no optimization of the C++ code, and in the other four runs, the compiler generated fully optimized C++ code. The unoptimized C++ code took roughly 32 times as long as the AVX-512 assembly code. The fully optimized C++ did a lot better, but still took about 3.2 times as long to run. Even with fully optimized C++ code, there is a noticeable performance hit due to the presence of the if … else logic in the for loop, which is shown in the C++ code just below.
The first column shows the elapsed times, in clock cycles (“clocks”), of the C++ for loop when the program is compiled with no optimizations. The second column shows the elapsed times with full optimization of the same loop. The third column shows the times for the AVX-512 assembly routine. The numbers in the fourth column are the ratios of the times for the optimized C++ code to those of the assembly routine.
| C++ code | C++ code (opt) | AVX-512 assembly code | Ratio |
|---|---|---|---|
| 918,745 | 106,988 | 29,840 | 3.59 |
| 895,560 | 85,036 | 29,912 | 2.84 |
| 899,154 | 71,316 | 23,340 | 3.06 |
| 895,596 | 98,032 | 30,538 | 3.21 |
Code Listing
C++ Driver
// SortPosNeg.cpp - Calculate the sums of positive and negative numbers in an array
#include <iostream>
#include <random>
// Prototype for assembly routine
extern "C" void PosNegSums(unsigned int count, int Arr[], int* PosSum, int* NegSum);
const int ArrLen = 12800;
using std::cout;
using std::endl;
int __declspec(align(64)) Arr[ArrLen]; // Align the array on a 64-byte boundary
int main()
{
// Generate an array of random values, uniformly distributed between -20 and 20.
std::mt19937 gen(1729);
std::uniform_int_distribution<> distrib(-20, 20);
int PosSum, NegSum;
int PSum = 0, NSum = 0;
// Fill the array from the uniform distrubution
for (int i = 0; i < ArrLen; i++)
Arr[i] = distrib(gen);
// Call the assembly routine to find the positive and negative sums
// Times for this call are shown in the table above
PosNegSums(ArrLen, Arr, &PosSum, &NegSum);
// Find the positive and negative sums using a C++ loop with if...else logic
// Times for this for loop are shown in the table above
for (int i = 0; i < ArrLen; i++)
{
if (Arr[i] >= 0) PSum += Arr[i];
else NSum += Arr[i];
}
// Display the results of both methods
cout << "PosSum: " << PosSum << endl;
cout << "NegSum: " << NegSum << endl;
cout << "PSum: " << PSum << endl;
cout << "NSum: " << NSum << endl << endl;
}Assembly Code
; SeparatePosNeg.asm
.code
PosNegSums PROC C
; Prototype: extern "C" void PosNegSums(unsigned int count, int Arr[], int* PosSum, int* NegSum);
; Calculate the sums of positive numbers and negative numbers in an array.
; Parameters:
; Number of elements in Arr in RCX
; Address of Arr in RDX
; Address of sum of positive values in R8
; Address of sum of negative values in R9
; Prologue
push rdi ; RDI is a non-volatile register, so save it.
sub rsp, 20h
mov rdi, rsp
vzeroall
shr rcx, 4 ; Divide by 16, since we can process 16 ints (64 bytes) per iteration
;------------- Loop that processes the numbers in the array
L1:
vmovdqa32 zmm3, zmmword ptr[rdx] ; Get 16 ints
vpcmpd k1, zmm3, zmm0, 5 ; Compare (not less than) ints in zmm3 with 0 value of zmm0
knotw k2, k1
vpaddd zmm1 {k1}, zmm1, zmm3 ; Selectively add the pos. values to the accumulated sum
vpaddd zmm2 {k2}, zmm2, zmm3 ; Selectively add the neg. values to the accumulated sum
add rdx, 64 ; Increment array address to next 16 ints
loop L1
;-------------------------------------------------------
; zmm1 is a vector with 16 partial sums of the positive values
; Convert zmm1 to two ymm regs, each with 8 ints
vmovaps zmm4, zmm1
vextracti32x8 ymm5, zmm4, 1
; zmm2 is a vector with 16 partial sums of the negative values
; Convert zmm2 to two ymm regs
vmovaps zmm6, zmm2
vextracti32x8 ymm7, zmm6, 1
; Contents of zmm1 are now in ymm4 and ymm5
; Contents of zmm2 are now in zmm6 and zmm7
; Get the sum of all of the positive numbers
; Each horizontal addition combines two of the partial sums
vpaddd ymm0, ymm4, ymm5 ; Add the two halves and put in ymmm0
vphaddd ymm0, ymm0, ymm0 ; Four partial sums are duplicated in upper and lower
; halves of ymm0
vpermq ymm0, ymm0, 0d8h ; Swap 2nd and 3rd qwords of ymm0 -- 0d8h == 11 01 10 00
; Now the four partial sums are all in xmm0
vphaddd xmm0, xmm0, xmm0 ; Two partial sums are now in low half of xmm0
vphaddd xmm0, xmm0, xmm0 ; Final sum is now in low dword of xmm0 (and duplicated in other parts)
vpextrd eax, xmm0, 0 ; Extract the dword at index 0 from xmm0
mov dword ptr[r8], eax ; Save the sum of all positive numbers to memory
; Same comments as the block above, but now we're getting the sum of the negative numbers
vpaddd ymm1, ymm6, ymm7
vphaddd ymm1, ymm1, ymm1
vpermq ymm1, ymm1, 0d8h
vphaddd xmm1, xmm1, xmm1
vphaddd xmm1, xmm1, xmm1
vpextrd eax, xmm1, 0
mov dword ptr[r9], eax ; Save the sum of all negative numbers to memory
; Epilogue
add rsp, 20h ; Adjust the stack back to original state
pop rdi ; Restore RDI
ret
PosNegSums ENDP
END
Former college mathematics professor for 19 years where I also taught a variety of programming languages, including Fortran, Modula-2, C, and C++. Former technical writer for 15 years at a large software firm headquartered in Redmond, WA. Current associate faculty at a nearby community college, teaching classes in C++ and computer architecture/assembly language.
I enjoy traipsing around off-trail in Olympic National Park and the North Cascades and elsewhere, as well as riding and tinkering with my four motorcycles.






The articles brought back memories!
As our university changed machines, which happened from time to time since the 70's, a professor of ours took the old machine and held Assembler courses which included visits of this machine. One could set addresses manually by setting a row of switches. The result could be seen via small red lights. The entire machine was fed with punched cards.
And before some kids will drop comments as "vintage" or "long ago", I'd like to answer: It is far less old fashioned than one might think! Many programs deal with huge amounts of data: telephone companies, transportation companies (railroad companies, airlines, airports, etc.), energy suppliers, meteorologists and so on. They often still run their machines set up in the last century and any modern replacement is often difficult to impossible. People's fear of the millenium bug wasn't because of the missing bits for the millenium, it was because of these old machines and codes, written somewhen in the 70's and still active. Myself has read thousands of codelines, many in Assembler, only to check whether the millenium bug can do any harm. Modernization is often impossible, because of the lack of knowledge in this sector, not because nobody wants to do it. Furthermore, someone has to write the C++ compilers.
The next revolution will probably be quantum computing, but it is a misinformation that all algorithms will speed up. It depends on their ability to be parallelizable. I already see the managers of tomorrow demanding a switch to quantum computing, but nobody can handle the old codes anymore! And what is written and has lived for decades cannot be renewed only because some economists think it can.
So in this sense, the articles are far more relevant than youngsters might think, if they read "Assembler".